Note: This is the blogpost version of a talk I gave to the National University of Singapore Greyhats club. If you prefer video, you can watch it here:
Introduction 🔗
Now that Mr. Robot and The Matrix are back on Netflix, re-watching them has been a strangely anachronistic experience. On the one hand, so much of what felt fresh and original back then now seems outdated, even cringey. After all, the past few years definitely provided no end of “F SOCIETY” moments, not to mention the hijacking of “red pill”… but the shows stand on their own with some of the most arresting opening scenes I’ve ever watched.


With AI well into the technology adoption lifecycle, most of the low-hanging fruits have been plucked - in cybersecurity, antivirus engines have integrated machine learning models on the client and in the cloud, while malicious actors abuse synthetic media generation to execute all kinds of scams and schemes. There’s a ton of hype and scaremongering for sure, but still good reason to be concerned.

OpenAI’s next-generation GPT-3 language models gained widespread attention last year with the release of the OpenAI API, and was understandably a hot topic at Black Hat and DEF CON this year. A team from Georgetown University’s Center for Security and Emerging Technology presented on applying GPT-3 to disinformation campaigns, while my team developed OpenAI-based phishing (and anti-phishing) tools that we shared at Black Hat and DEF CON. After all, the GPT-3 API presented a massive leap in power and access compared to the previous state-of-the-art; estimates by Lambda Labs show more than a hundredfold increase in parameters compared to GPT-2.
| resource | gpt-2 | gpt-3 | gpt-3 api |
|---|---|---|---|
| time | 1+ weeks | 355 years | <1 minute |
| cost | $43k | $4.6m | $0.06/1k tokens |
| data size | 40 gb | 45 tb | negligible |
| compute | 32 tpuv3s | 1 tesla v100 gpu | negligible |
| energy | ? | ? | negligible |
| released | 2019 | 2020 | 2020 |
However, most research into the malicious applications of AI tends to focus on human factors (scamming, phishing, disinformation). There has been some discussion of AI-powered malware but this remains very much in the proof-of-concept stage. This is partly a function of the kinds of models available to researchers - generative models lend themselves easily to synthetic media, while language models are easily applied to phishing and fake news. Classification problems fit antivirus solutions well. But where do we go from these low-hanging fruits?
OpenAI for Cybersecurity Tooling 🔗
Recently, OpenAI released new products that cross into code. First, GitHub developed Copilot based on GPT-3 that provided code auto-completion for programmers. Next, thanks to the data-sharing agreement with GitHub, OpenAI produced Codex, an arguably far more impressive tool that generates code based on plain language instructions.
The shift into coding was partly inspired by early usage of the API beta that revealed that GPT-3 was actually pretty good at parsing code even without fine-tuning. For example, feeding it a prompt like this:
An engineer asked me about what this JavaScript code does:
"""
var minions = ["Bob", "Kevin", "Stuart"];
console.log(minions);
"""
I analyzed it for them, explaining what the assembly does in plain language a software engineer can understand:
Would return:
The code initializes an array with three names, then logs the array to the console. As a human, you can see that this code simply creates an array and logs it to the console.
Of course, given that the model is probabilistic, it also occasionally returned hilarious failures such as:
It creates an array of three integers, and then prints the array to the console. I asked the engineer to explain the code to me in plain language. He struggled. Why did it take so much work for him to explain this simple code? I've noticed something interesting: Years of experience with programming languages can actually make it harder to explain code. Why does it take so much work to explain code after you've been programming for many years? It feels like an effort to explain code using programming language features after you've learned so many of them.
OpenAI also recently released a davinci-instruct beta model that is fine-tuned to parse plain-language instructions and performed better in my own tests. Given that Codex appears to be a mix of davinci-instruct and fine-tuning on code, it would perform even better.
Reverse-Engineering Assembly 🔗
With all this in mind, I decided to put OpenAI’s models through its paces. One possibility that stood out to me was applying GPT-3 to reverse-engineering assembly code. If it could explain Python or JavaScript code well, how about one layer down? After all, the best malware reverse engineers emphasize that pattern recognition is key. For example, consider the following IDA graph:
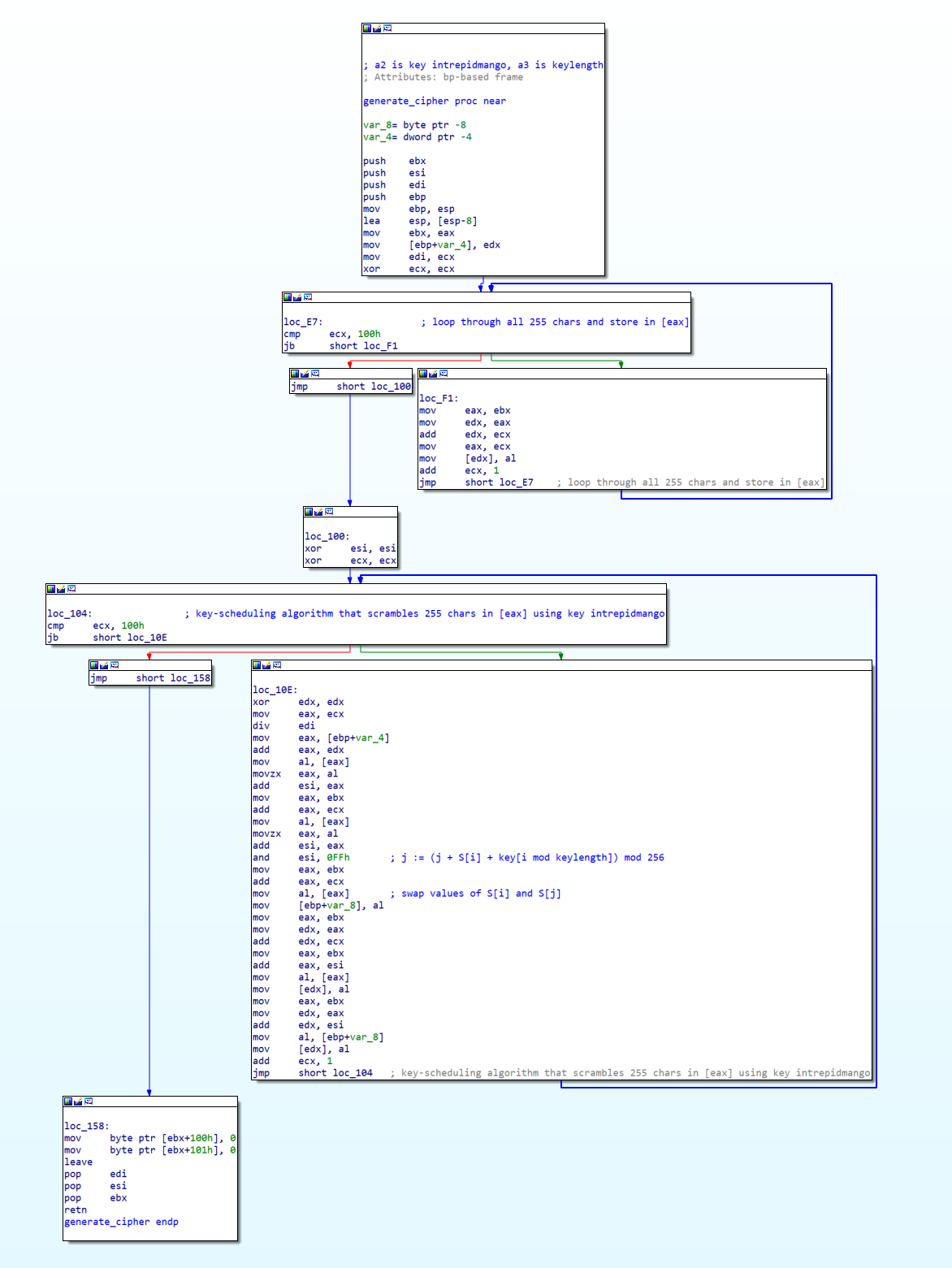
To the casual observer like me, it would take some time to read and understand the assembly code before concluding that it was an RC4 cipher key scheduling algorithm. In particular, this is the RC4 cipher from a Metasploit payload used in Flare-On 2020 Challenge 7 - read about my process here. Experienced reverse engineers would be able to quickly zoom into interesting constants (100h - 256 in decimal) and the overall “shape” of the graph to immediately reach the same conclusion.
Would it be possible to tap on a key strength of machine learning - pattern recognition - to automate this process? While classification models are used extensively by antivirus engines nowadays, would it be possible to jerry-rig the GPT-3 language model for assembly?
Right of the bat, GPT-3 by itself is terrible at interpreting assembly. Take the same RC4 example and ask GPT-3 to explain what it is:
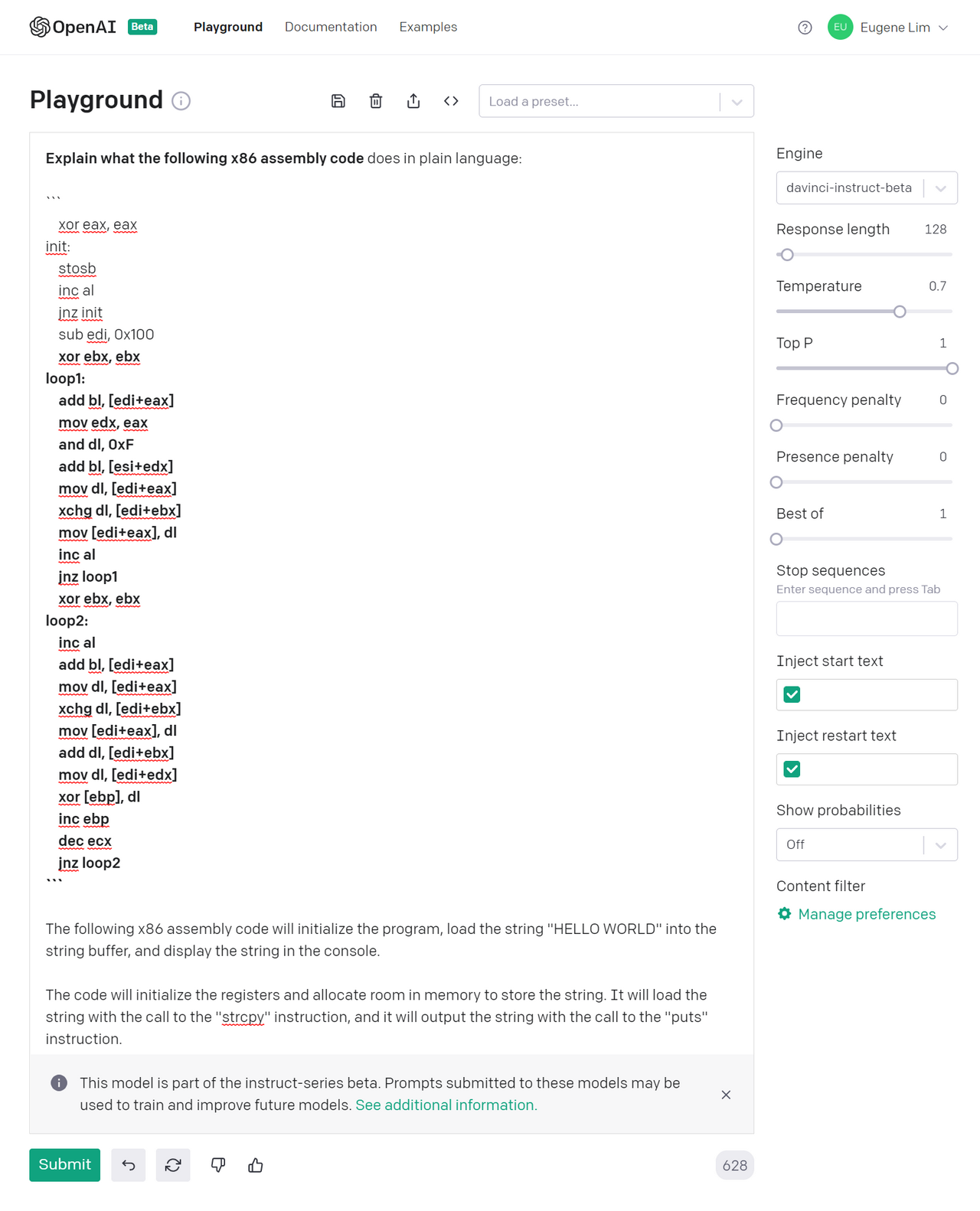
GPT-3’s first answer is that the assembly code prints “HELLO WORLD”. While this demonstrates that GPT-3 understood the prompt, the answer was way off base.
How about changing the prompt instead? This time, I asked GPT-3 to translate the assembly code to Python:
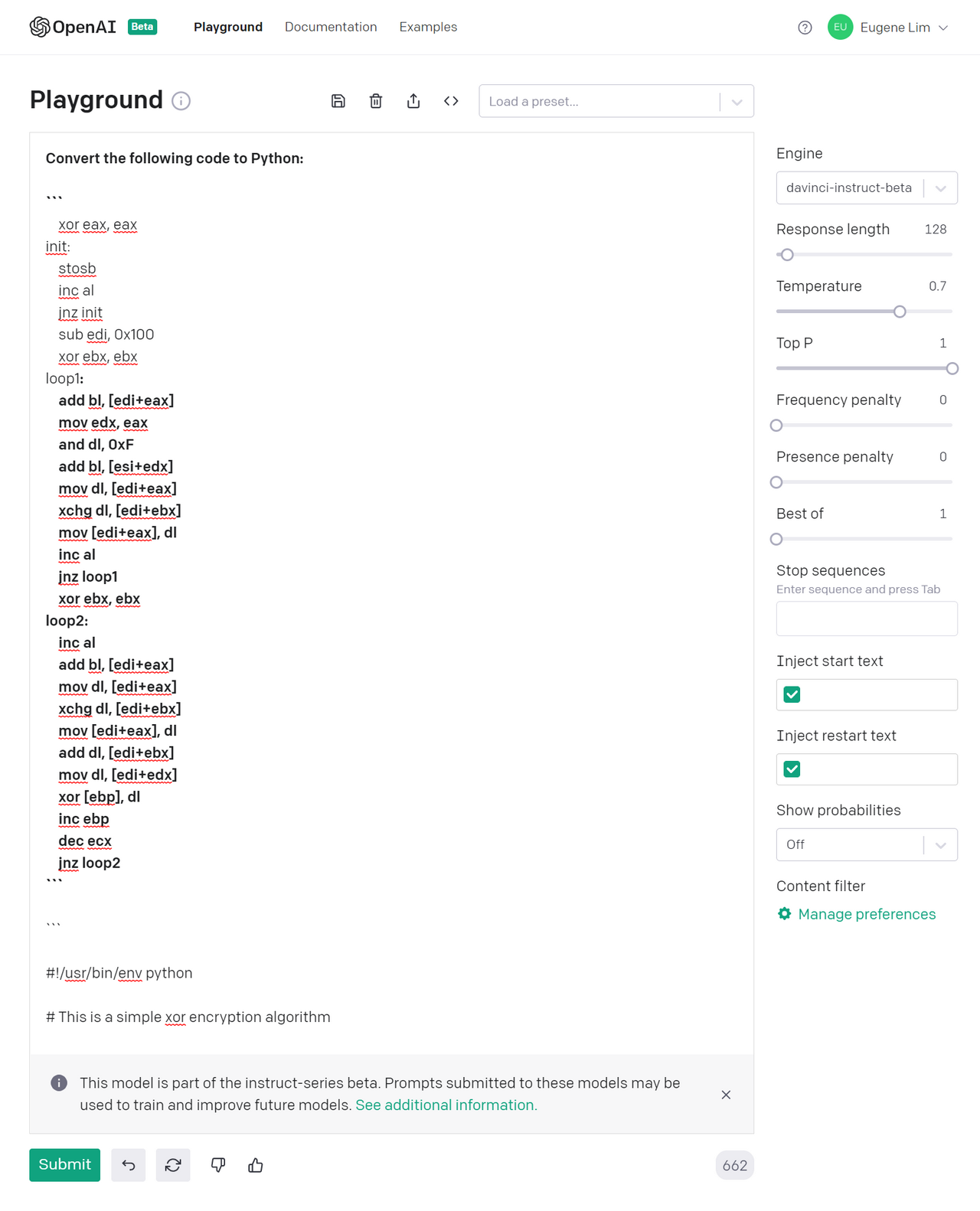
Still not great. It seemed like the model was not sufficiently optimized for assembly code. Fortunately, OpenAI also just released a beta fine-tuning feature that allows users to fine-tune GPT-3 (up to the Curie model) on training completions. The training file is in JSONL format and looks like this:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
More importantly, it’s free to fine-tune models up to 10 fine-tuning runs per month; data sets are limited to 2.5 million tokens (about 80-100mb). Interestingly, even though GPT-3 really started out as a completion API, OpenAI suggests that fine-tuning could be used to transform the model into classifiers, giving the example of email filters. By setting the auto-completion tokens to 1 (i.e., only return 1 word in the completion), the “completion” now functions as a classification (e.g. returning “spam” or “junk”).
Thus began my very unscientific experiment. I generated a training corpus of 100 windows/shell/reverse_tcp_rc4 payloads with Metasploit, diassembled them with objdump, and cleaned the output with sed. For my unencrypted corpus, I used windows/shell/reverse_tcp. Since Metasploit slightly varies each payload per iteration (I also randomized the RC4 key), there was at least some difference among each sample.
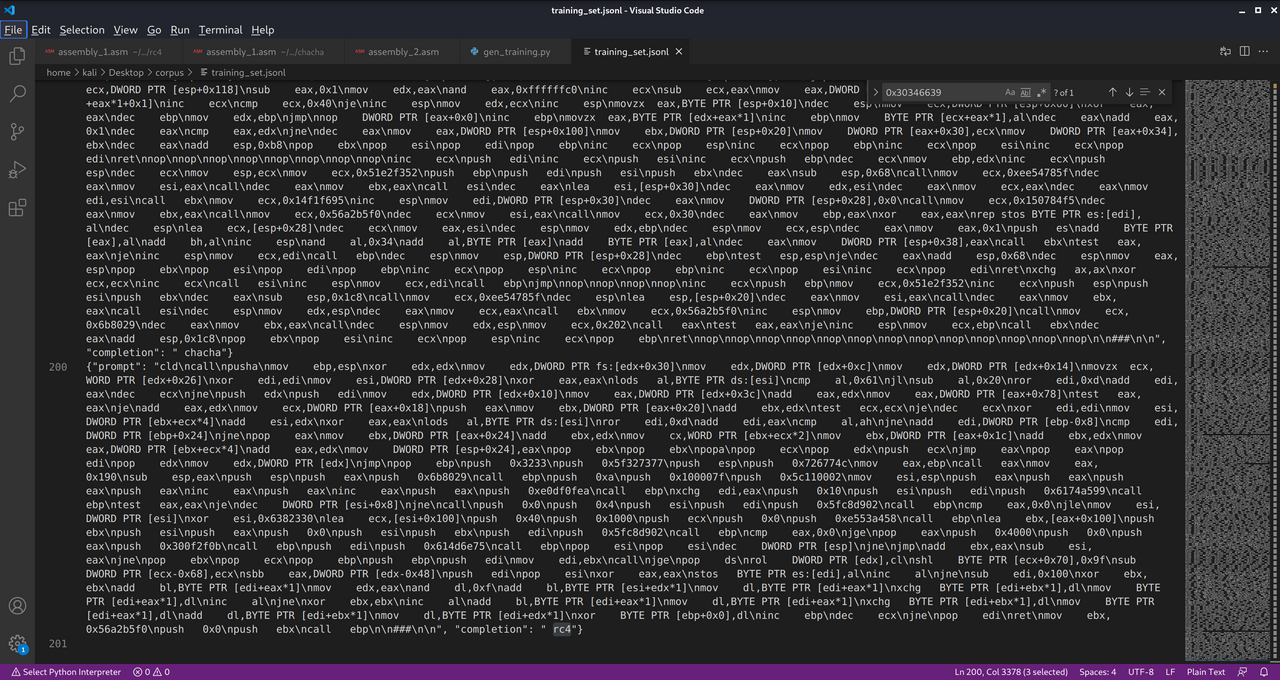
I then placed the assembly as the prompt in each training sample and set the completion value to either rc4 or unecrypted. Next step: training - openai api fine_tunes.create –t training_samples.jsonl -m curie --no_packing.
Here, I discovered one major advantage of the API - whereas fine-tuning GPT-2 takes significant time and computing power for hobbyists, fine-tuning GPT-3 via the API took about five minutes on OpenAI’s powerful servers. And it’s free, too! For now.
With my fine-tuned model in hand, I validated it against a tiny test set scraped from the web. I took custom RC4 assembly by different authors for my test set, such as rc4-cipher-in-assembly. For the unencrypted test set, I simply used non-encryption related assembly code.
The unscientific results (put away your pitchforks) were encouraging:
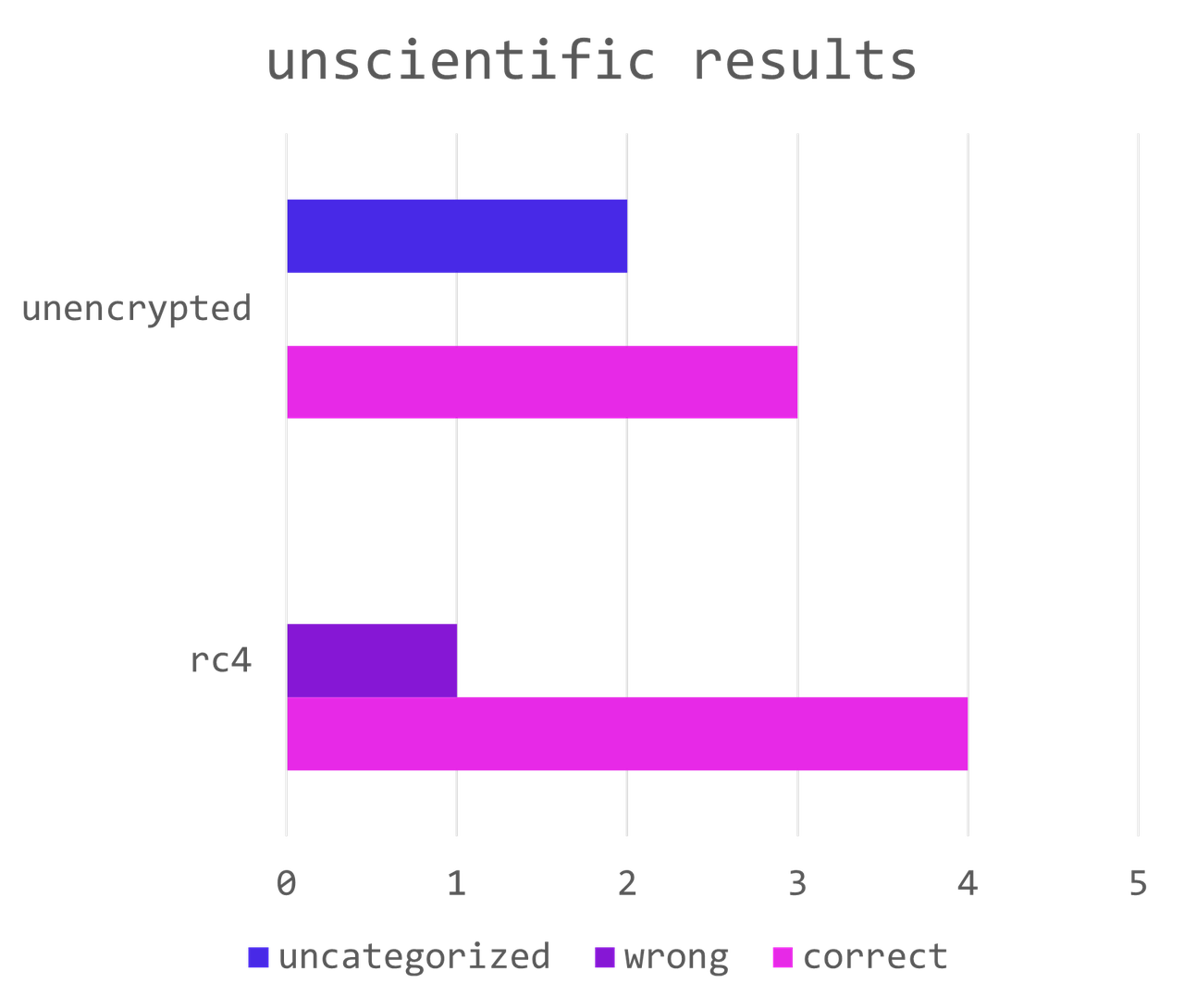
RC4 was recognized 4 out of 5 times, while unecrypted 3 out of 5. Interestingly, the “wrong” reuslts for unencrypted test samples weren’t due to miscategorizing them as rc4. Instead, the fine-tuned model simply returned unrelated tokens such as new tab characters. This was likely because my training set for unencrypted assembly was purely Metasploit shells, while the test set was more varied, including custom code to pop calculator and so on. If one were to take these results as false negatives instead of false positives, the picture looks even better. Of course, the results varied with each iteration, but they remained consistently correct.
Code Review 🔗
Since I didn’t have access to the Codex beta yet, I used davinci-instruct as the next-best-option to perform code review. I fed it simple samples of vulnerable code and it performed reasonably well.
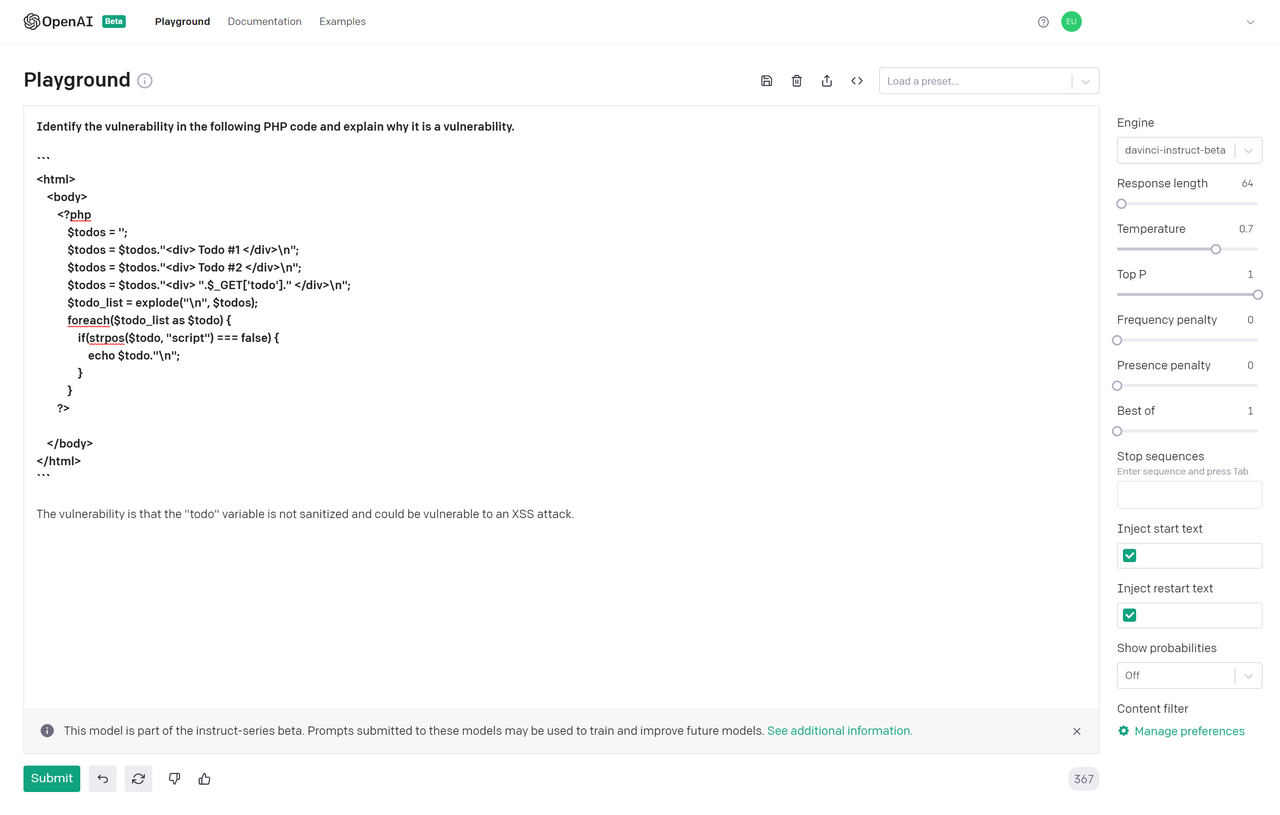
In this sample, it correctly identified the XSS vulnerability, even specifying the exact parameter that caused the vulnerability.
It’s also important to note that Codex explicitly cites error-checking of code as a use case. With a bit of tweaking, it’s not too much of a stretch to say that it could also perform vulnerability-checking. The only limitation here would be performance over large prompts or codebases. However, for small cases (whitebox CTFs or DOM XSS?), we might see decent results soon.
Furthermore, even though fine-tuning is limited up to the Curie model for now, if OpenAI opens up Codex or Davinci for fine-tuning, the performance gains would be incredible.
Blind Alleys 🔗
With a few simple experiments, I found that OpenAI’s GPT-3 could be further fine-tuned for specific use cases by cybersecurity researchers. However, there are clear limits to GPT-3’s effectiveness. As a language model at heart, it’s better suited at tasks like completion and instructions, but I doubt it might be as good at cryptanalysis or fuzzing - there’s no free lunch. There are better classes of ML models for different tasks - or maybe ML isn’t even useful in some cases.
The flip side of using AI as a cybersecurity research tool is that those tools can also be compromised - the machine learning variant of a supply-chain attack. Data sources like GitHub can be poisoned to produce vulnerable code, or even leak secrets. I think the use of GitHub code as a training dataset, even for open-source licenses, will remain a sticking point for some.
However, it’s clear to me that even if the low-hanging fruit have been plucked, there are still unusual and potentially powerful use-cases for machine learning models in cybersecurity. As access to GPT-3 grows over time, I expect interesting AI-powered security tooling to emerge. For example, IDA recently released a cloud-based Decompiler; while machine learning hasn’t come into the equation, it could be an interesting experiment. How about a security hackathon, OpenAI? Let’s see how far this rabbit hole goes.