This post was originally published on the Open Government Products Substack. ICYMI: I’m publishing a book with No Starch Press! I wrote “From Day Zero to Zero Day” for newcomers looking to enter the rarefied world of vulnerability research. I will be speaking at DEF CON (stay tuned) and doing a book signing, so see you at Hacker Summer Camp!
Nobody cares about the infrastructure you build. Users of your tool will never understand it as deeply as you do or care about it as much as you do… The less time they spend thinking about your tool, the happier they are. A day where they’re forced to think about your tool unexpectedly is a bad day for them.
This sensibility needs to be deeply embedded in the UX for tools. Easy-to-use infrastructure isn’t about well-written changelogs and developer guides, it’s about building tools that people can use without having to read any documentation at all.
Jay Gengelbach, Software Engineer at Vercel
This is the second in a series of blogposts on first principles in building cybersecurity solutions at Open Government Products (OGP).
Moving from offensive security to security engineering, one of the thing I noticed is how many challenges security has in common with other internal tooling teams, such as devops, platform engineering, and site reliability engineering. Just replace “infrastructure” with “security tools” in Jay’s quote above (in fact, read the whole LinkedIn post) and you’ll see what I mean.
This is the critical realisation: security isn’t the first priority for everyone. Even if the security team thinks security should be at top of the list, the reality is that there’s a lot more to worry about - keeping services up, developing the next feature, and ensuring infrastructure bills get paid. However, our security tools often doesn’t reflect this reality.
I’ve evaluated security solutions that are plainly geared towards the “133t h4x0r” archetype, from real-time cyber attack maps to cyberpunk illustrations of APTs with spooky names. These flourishes don’t actually match up to the core work of most cybersecurity teams. While we would like to imagine we’re all fighting APTs daily, many organisations are more likely to be brought down by Advanced Persistent Teenagers due to simple weaknesses in their attack surface.
In addition, while a case can be made for specialised tools meant just for cybersecurity teams, not every organisation can stand up a full-scale security operations center. Instead, modern security programmes embrace DevSecOps and “Shift-Left” platforms that target developers and maintainers. How can we expect software engineers, system administrators, and non-cyber specialists to use security tools effectively if they’re not designed for them?
Ross Haleliuk captured “these obvious facts worth reminding ourselves about”:
- Most security practitioners are just doing our jobs
- Most companies are not tech companies
- Most people outside of security don’t care (and won’t care) about security
What happens when security teams lose sight of these “obvious facts”?
Frictionware 🔗
Let’s dive into another fictional example:
*Jane Doe’s management recently procured a top Gartner Magic Quadrant cybersecurity solution. It promises to detect and block any potential attacks on their AI apps, and it actually does it pretty well. In particular, management was impressed by the flashy dashboards. Excited about its capabilities, Jane Doe takes on the task of rolling it out in the organisation.
However, she quickly hits a roadblock. Due to the way the organisation is set up, there are numerous accounts and resources spread out across multiple teams. In order to onboard to the platform, teams need to perform multiple configuration steps, such as opening up network firewall rules. In addition, the platform runs scans that incur compute and storage costs.
Teams are slow to onboard, citing more pressing priorities and concerns about costs or maintenance. It doesn’t help that a handful of early adoptees ran into unexpected bugs that brought down production. Debugging these issues takes significant effort due to limited access and engineering resources.
Jane seeks management’s support to improve the rollout and gets it. With more delivery managers, Jane can engage more teams at once. The rate of onboardings increase, but so does the number of technical issues. The team is getting overwhelmed with bug reports, chasing belligerent teams, and other busywork.
On top of it all, Jane is notices another worrying trend - after onboarding, no one’s actually using the platform. Detections are piling up, and beyond the base configuration, few are taking advantage of the advanced features. She wants to study this issue more, but everyone’s tied up with chasing teams to onboard. It’s already been six months and the deadline is approaching…*
Unfortunately, despite investing more resources, it appears that the security team is now more focused on onboarding users by any means possible rather than achieving actual security outcomes. While some onboarding lift may be necessary in many situations, could this rollout have gone better?
This is the second cybersecurity antipattern: frictionware.
What Creates Frictionware? 🔗
Frictionware is security tooling that creates significant friction in adoption and usage, requiring significant manual effort simply to maintain coverage. Imagine rolling a large stone uphill. The slope is littered with obstacles and uneven surfaces, making the journey more difficult. The moment you let go, the stone rolls back down. Similarly, without continuous onboarding efforts, frictionware will quickly be abandoned by its users. Let’s examine some common causes of frictionware.
Complex Onboarding 🔗
The first problem is needing to onboard at all. In an ideal world, your organisation has sufficient central platforms that allow you to roll out additional security controls invisibly to end-users. The moment you require some kind of manual intervention by users, your resourcing requirements will start to scale with the size of your user base. Now you have to deal with user error, customer service, and other bureaucratic overheads.
However, we don’t always live in an ideal world and some onboarding is still necessary. Consider how most (successful) consumer-facing tech products design their onboarding flows. They optimise the process to maximise signups and reduce friction by any means possible, down to counting the number of clicks. Real user monitoring and metrics are rigorously analysed for potential blockers.
Failing to apply a similar approach to internal tools, including security, reduces productivity across the org. In Jason Chan’s excellent “Security for High Velocity Engineering” blogpost, he states another “obvious fact”:
Security teams are centralized teams - by handling security, we support the entire business. Other centralized teams include legal, human resources, facilities, and IT. The one rule that all centralized teams share - you must grow sublinear to company growth.
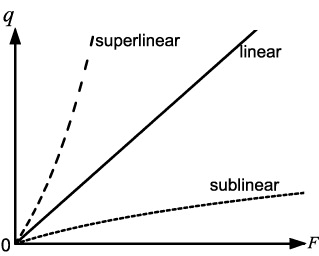
In Jane’s case study, she needed to add more and more team members just to keep up with the onboarding operations. If team growth is capped, this can also result in overworked staff, late hours, and cannibalising from other security project teams.
For end-users, Jason shared another important insight:
Early on in my time at Netflix, we looked at some data that showed the average tenure for an engineer was around 18 to 24 months. That is the amount of time you have to get an engineer productive and delivering to benefit the business. How do you want to spend that time? It’s not in security training and awareness education. Rather, you want to invest your resources in making your security systems and interfaces simple and easy to use for even brand new engineers.
In Jane’s situation, regular software engineers were forced to dedicate extra hours and context-switch to perform the onboarding as well as debug technical issues. The real total cost of operation was much higher than what Jane’s team had on paper. The less onerous your onboarding process, the more value you can unlock for the organisation. This requires stepping away from security silos and focusing on real outcomes like ”exploitable vulnerabilities identified and resolved”, not vanity metrics like “coverage” or “number of users”.
Weak Value Proposition 🔗
The second problem is not generating value for users - especially non-security benefits. In his Substack, Ross Haleliuk talks about two types of organisations where security and compliance are existential risks - top targets like cryptocurrency exchanges or heavily-regulated industries like healthcare and financial services. However, most organisations don’t fall under these two categories. In these situations, security isn’t a given and must compete with other priorities:
As soon as the stakes get higher, this picture changes. The moment there is a risk that security can impact the ability of the company to ship a key feature by a certain date, hit a quarterly revenue target, or launch a critical partner integration, security doesn’t get to say “No”. The truly consequential business decisions, the ones that carry strategic weight, are made by product, engineering, go-to-market, and executive teams. In those rooms, security is at best an advisor, but not a key player with the power to say “No”.
Is your tool making things easier for the end-user, and not just the security team’s? Does it help them get better visibility over things they care about, like cost attribution? Or does it make their life harder?
Even then, most reasonable people would be willing to be inconvenienced if it’s a real security issue. How confident are you that the interrupts generated by your tool are generating real value on that front?
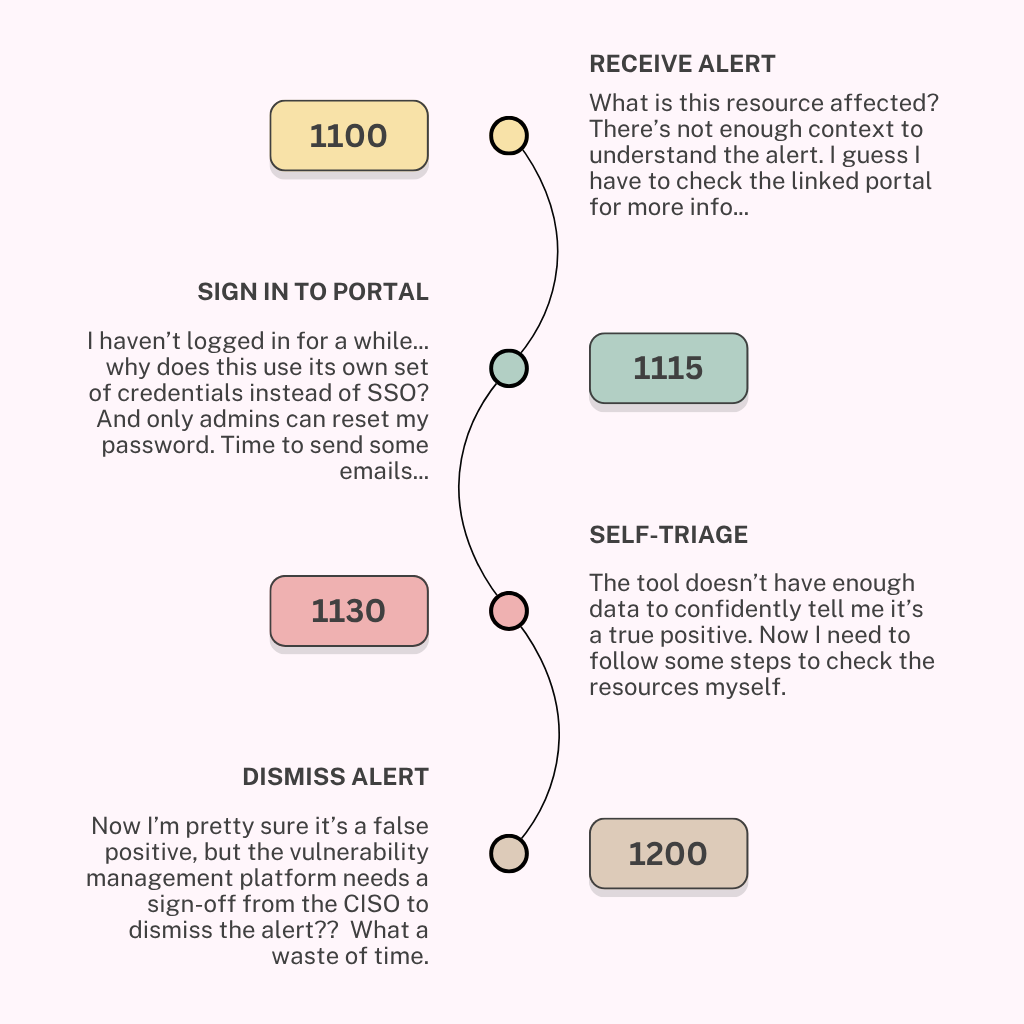
In the user journey above, unoptimised vulnerability management frameworks end up creating more busywork for others due to low signal-to-noise. Over time, this can lead to alert fatigue, eventually undermining the main purpose of the tool. In addition, the total cost of operations is hidden from the security team, because all of this busywork is done by the end-user.
Lack of Integration and “Security Sprawl” 🔗
In Jane’s scenario, one issue was lack of usage. Consider the typical daily workflow of a developer: they’re probably bouncing from their IDE, to GitHub or GItLab, checking Slack, maybe a task tracker, and occasionally looking into their observability tools like DataDog or Elastic. How often are they excitedly jumping into security tools or dashboards? Probably not unless they really have to.
If your tool forces users to jump out of their usual workflows, fumble around for credentials, and figure out the user interface from scratch, it creates a ton of additional friction. In addition, sometimes security teams operate multiple tools and platforms, each with their own separate interfaces and dashboards, creating multiple sources of truth and forcing constant context-switching.
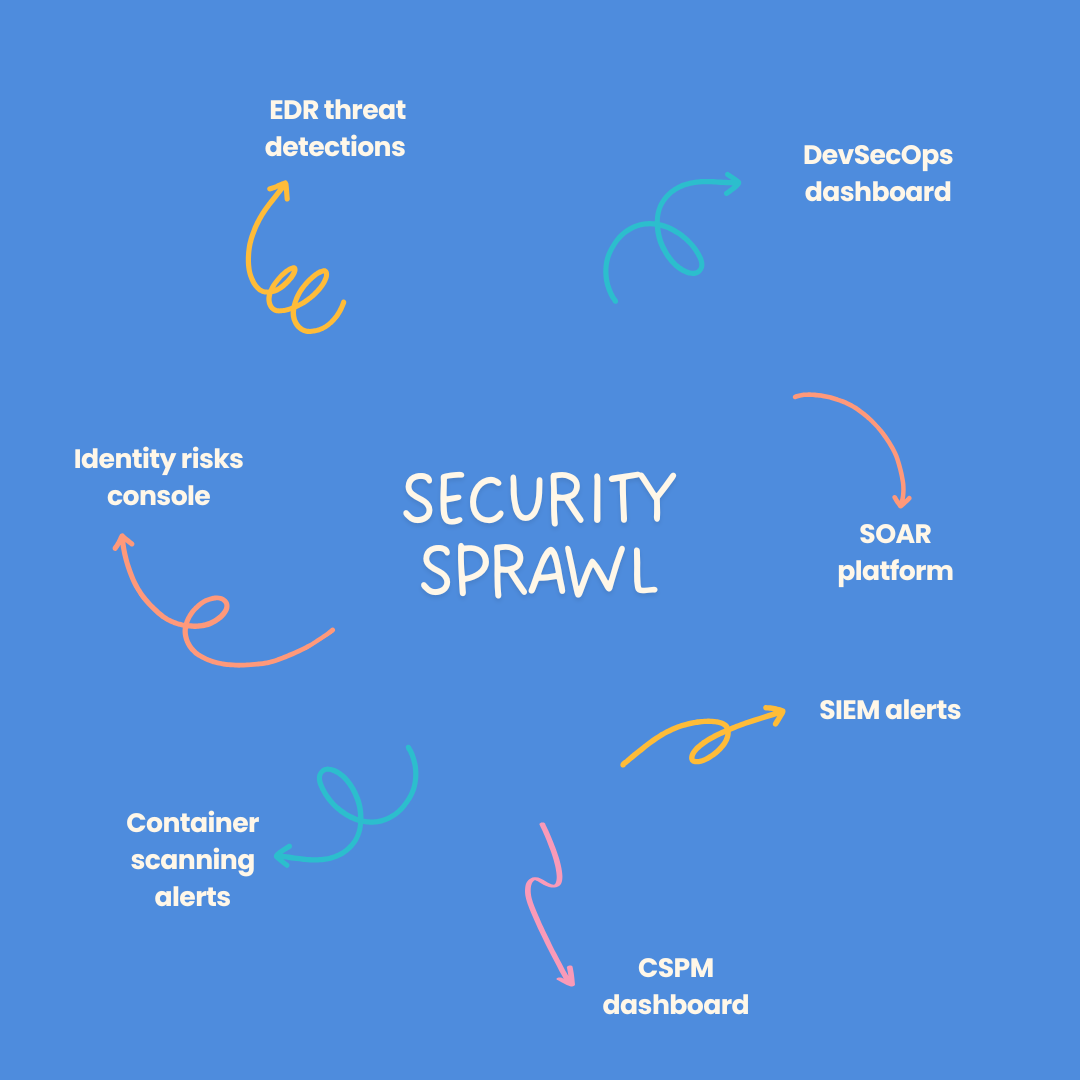
How do you avoid Frictionware? 🔗
Build-In, not Opt-In 🔗
The best way to avoid onboarding friction is to not require onboarding at all. For example, if you need cloud visibility, you can easily achieve this using delegated administrator rights across an entire AWS Org. The key is working with platform engineers and other internal tooling teams who hold the keys to these levers.
However, one corollary is that building-in shouldn’t break anything. Having super-admin might be awesome, but the moment you flip a switch that breaks production, expect to have that privilege taken away very quickly. This constrains the scope of many built-in mechanisms to read-only visibility. This is why Ross Haleliuk highlighted visibility as the one of the few areas security teams can fully control:
The fact that visibility is now the core function of the security team is a direct consequence of how complex the role has become. Security teams today are navigating fast-moving product roadmaps, decentralized architectures, and growing regulatory pressures, often with limited authority and resources. In that environment, all security teams in most organizations are given the power to do is to get visibility into their risks.
While this might sound a little fatalistic, it’s important to leverage that visibility to help prioritise higher-impact tasks that require greater intervention. Visibility highlights hot spots that you can take to management to justify stronger prevention mechanisms.
On that note, some prevention mechanisms can still be built-in with minimal disruption. These are high-signal, detect-and-block tools such as secret push protection to prevent secrets being committed to code, as well as “invisible” security such as hardened container images injected into the internal container registry. To achieve this, the security team must once again collaborate with other internal tooling teams to build up the platforms that make this possible in the first place - common CI/CD pipelines, container registries, internal packages, and so on.
At OGP, the security team prioritised important upgrades - SSO, Enterprise plans, organisation/multi-tenant consolidation - that unlocked these built-in mechanisms for us. While many of these upgrades may not have had a direct “security” link at that time, they enabled far more effective interventions beyond visibility.
Use Forcing Functions 🔗
Sometimes, not everything can be seamlessly built-in. You may need your users to perform some configuration steps, even though I’d argue that this is a symptom of missing high-leverage mechanisms (see Kelly Shortridge: “Every hardening guide recommendation is a missed opportunity for a safer default”). In any case, having to track and chase everyone to complete every step isn’t a scalable tactic.
In this case, you can utilise forcing functions. These are key funnels in users’ workflows where you can implement onboarding requirements in order to proceed to the rest of the workflow. For example, you may want all deployed resources to be properly tagged and meet certain hardening configurations. One industry colleague utilised Kyverno Policy-as-Code gates to enforce these requirements before any resource was allowed to be deployed to the organisation’s central Kubernetes cluster. No secure configuration, no production deploy. Some organisations regularly delete resources that were left untagged past a certain time period - the classic scream test.
All of this sounds pretty harsh because you’re directly impacting users’ ability to deploy to or stay in production. This is why forcing functions must be carefully designed:
- The reason for failing a forcing function is clear and immediately visible to the user.
- It’s simple to self-resolve a failed forcing function.
If you introduce a forcing function into users’ workflows, you must commit to making it simple and easy to pass. Impose SLAs on your own team if you need to - this is the responsibility of the forcing function’s owner.
Identify and Target Centres of Gravity 🔗
One of the biggest mistakes a security team can make is creating additional silos through their tooling. There are numerous security platforms and tools that sit separate from developers’ day-to-day workflows, but it’s unlikely that a regular developer will want to venture out of their usual screens unless they absolutely have to. These are where the real centres of gravity lie.
Data Centres of Gravity 🔗
Consider Jane’s scenario which required system owners to send their data out of their systems to the security platform. Was this really necessary? Was there somewhere else where this data was already being stored, enriched, and analysed?
This issue is why many observability platforms and cloud service providers have been able to pivot into the lucrative security space. While they originally started out solving developers’ problems by providing logging and monitoring capabilities, they quickly realised that the same data was invaluable to security use cases. This LinkedIn post by Mike Wiacek, the co-founder of Google Chronicle, is particularly revealing:
In 2009, I was sitting in a Google conference room eating a burrito when I got pulled into one of the most formative security incidents of my career: Operation Aurora.
For me, it didn’t start with a red alert. It started with a burrito.
We quickly ended up with a whiteboard covered in C2 hostnames, shifting IOCs, and a team trying to trace an APT actor across massive infrastructure.
Someone said: “Wouldn’t it be nice if we could see every machine that ever looked up anything that ever resolved to any netblock this adversary ever touched?”
Across the table, Shapor Naghibzadeh, who later became my co-founder at Chronicle, said: “I have that DNS data. All of it.”
“Why? How?”
“Felt like it might be useful someday,” he said.
That was the unlock.
That’s when it clicked: 👉 SECURITY IS A DATA SEARCH PROBLEM. Not a policy problem. Not a compliance problem. Not a “check the box and hope” problem.
Very often, developers and system maintainers are already sending their logs somewhere because that visibility helps solve their own problems. Splunk, Elastic, DataDog and many other observability platforms all started out solving these problem statements before expanding into security.
In our case, when setting up our detection and response capability at OGP, we didn’t start out asking: “where should developers send their logs?” Instead, we asked: “where are developers already sending their logs?” and built our security stack on top of that. This cut down a large amount of onboarding effort because developers could simply tweak their existing toolchains (and security engineering could tweak these upstream) to add security-relevant logs, rather than sending it to a completely new destination.
Attention Centres of Gravity 🔗
Jason Chan also discusses another important goal of good security tooling: Maximize flow state.
Flow state, or uninterrupted time for deep work, must be optimized. Our security initiatives must respect flow state by minimizing unplanned work, unscheduled interruptions, and low-value meetings.
Part of maintaining a flow state is minimising disruptions that take you out of your workflow. This is where the centres of gravity of attention come into play. Ideally, security alerts and issues are integrated directly into the platforms that your users are already accessing daily, rather than pulling them out into a separate platform they’re unfamiliar with.
This motivates the consolidation of logging and observability with on-call and paging platforms - DataDog recently released DataDog On-Call to general availability, and Grafana released its combined Incident Response and Management product. There’s a huge platform play here combining observability, security, and response.
Part of the work of OGP’s security engineering team is building these integrations between our tooling and these attention centres of gravity - SlackOps, GitOps, and platform-native alerts. One added benefit is that when developers respond to these alerts, they can move much faster because they’re familiar with the user interface and features of existing platforms, reducing the time to contain and remediate issues.
Case Study: Subdomain Takeovers 🔗
At OGP, we have multiple product teams that have full ownership of their deployed resources, including domains. While this is great for development velocity and ownership, this can also lead to poor central management of infrastructure. As such, we experienced a number of subdomain takeover reports as teams failed to maintain their domain records on Cloudflare.
To tackle this problem, the security engineering team built a subdomain takeover monitoring tool that would pull all domain records from Cloudflare’s APIs and scan the for common subdomain takeover fingerprints. This was more efficient that an “outside-in” approach using attack surface management tools that bruteforced potential subdomains - instead, we could obtain the zone records directly from Cloudflare.
However, we faced an onboarding challenge due to the need to gain API access to multiple Cloudflare accounts. Cloudflare lacks a true multi-tenant concept similar to AWS Organizations (Cloudflare’s Tenant API is gated to Channel and Alliance partners/resellers), so we couldn’t “invisibly” get access through a delegated admin mechanism.
Instead, we had to manually onboard every account. While this might still work as a one-off effort, it wouldn’t solve the problem of onboarding future accounts without having to constantly remind users to do so - and remember, “good intentions don’t work, mechanisms do”.
In this case, we realised that if Single-Sign On (SSO) is enabled on Cloudflare for an organisation’s email domain, all future logins under that domain, even if it was on a different Cloudflare account, would have to go through SSO. This allowed us to use SSO as a forcing function to onboard to our domain monitoring tools:
- Product team wants to create a new Cloudflare account and is blocked by SSO (forcing function).
- As part of resolving the SSO blocker (which can be automated), product team are onboarded to the subdomain takeover tool.
In other words, “no subdomain takeover monitoring, no Cloudflare account”. Interestingly, using SSO as a forcing function is pretty common; checking Sign in with Google records is how many “Shadow IT” tools map out which apps an organisation’s users are using.
Zhong Liang Ou-Yang, our security engineer building the tool, also implemented a self-service GitOps onboarding and vulnerability management workflow, with additional Slack alerts. This minimised the ongoing maintenance effort to just “we’ll let you know if there’s a problem”, while ensuring engineers don’t have to leave their typical platforms.
In the long run, we plan to build out sufficiently high-leverage mechanisms so that we can build-in the subdomain takeover scanning (Cloudflare, please open up the Tenants API!) or via an official Cloudflare developer platform integration. However, simply having this visibility has already enabled us to also quickly perform quick scans for other common vulnerabilities across our entire attack surface, demonstrating the importance of building up multiple levers.
Conclusion 🔗
In this blogpost, I’ve explained how frictionware occurs and how to avoid creating them. In reality, rolling out security tooling across a heterogenous organisation isn’t easy. Many organisations lack high-leverage mechanisms to go for the “build-in” route, which is why it’s necessary to invest in creating these mechanisms even while addressing the most critical problems with existing alternatives.
More importantly, I hope to highlight that this is a self-perpetuating cycle: if you continue to build frictionware, your resourcing needs will grow linearly (or worse, super-linearly), diverting attention and resources away from building up good mechanisms, eventually sucking out all the oxygen from the room. What’s left is a demoralised, overworked security team more focused on vanity metrics than real security outcomes.