One common perception is that it is easier to write rules for Semgrep than CodeQL. Having worked extensively with both of these static code analysis tools for about a year, I have some thoughts. As a practitioner, I’m not required to know the exact workings of these tools, but a recent deep dive into their theoretical foundations inspired me to consolidate my thoughts here.
Syntax and Data Structures 🔗
CodeQL and Semgrep OSS are the main free code analysis tools with custom rule support. Unless you count writing XPATH queries and Java plugins as “custom rule support”. However, they differ greatly in terms of their rule syntax, which is also where most of the learning curve of CodeQL occurs.
CodeQL uses the QL language, which looks like a typical SQL query with select and where clauses:
/* github/codeql/blob/main/javascript/ql/src/Electron/AllowRunningInsecureContent.ql */
/**
* @name Enabling Electron allowRunningInsecureContent
* @description Enabling allowRunningInsecureContent can allow remote code execution.
* @kind problem
* @problem.severity error
* @security-severity 8.8
* @precision very-high
* @tags security
* frameworks/electron
* external/cwe/cwe-494
* @id js/enabling-electron-insecure-content
*/
import javascript
from DataFlow::PropWrite allowRunningInsecureContent, Electron::WebPreferences preferences
where
allowRunningInsecureContent = preferences.getAPropertyWrite("allowRunningInsecureContent") and
allowRunningInsecureContent.getRhs().mayHaveBooleanValue(true)
select allowRunningInsecureContent, "Enabling allowRunningInsecureContent is strongly discouraged."
However, this is a trap: approaching QL like a database query language will only lead to ruin. As their documentation notes, QL is based on Datalog, “a declarative logic programming language often used as a query language.” My take is that QL is an object-oriented programming language for making queries. In order to write good QL, you need to be very familiar with the various classes in the CodeQL standard library and their predicates (i.e. methods). In the query above, for example, you need to make sure preferences.getAPropertyWrite("allowRunningInsecureContent") returns a DataFlow::PropWrite instance in order for the equality comparison to work.
In contrast, Semgrep rule syntax is pattern-oriented. To visualize this, consider the following Semgrep rule that checks for the same vulnerability as the CodeQL example.
# ajinabraham/njsscan/blob/master/njsscan/rules/semantic_grep/electronjs/security_electron.yaml
rules:
- id: electron_allow_http
patterns:
- pattern-either:
- pattern: >
new BrowserWindow({webPreferences: {allowRunningInsecureContent:
true}})
- pattern: |
var $X = {webPreferences: {allowRunningInsecureContent: true}};
message: >-
Application can load content over HTTP and that makes the app vulnerable
to Man in the middle attacks.
languages:
- javascript
severity: ERROR
metadata:
owasp-web: a6
cwe: cwe-319
Overall, it seems easier for the untrained eye to understand what the rule is doing. Of course, this is playing on Semgrep’s home ground; in fact, even a regex search could have achieved this (hence the grep in Semgrep). The proving ground for high-quality rules that identify real vulnerabilities is taint tracking. While Semgrep only offers global taint tracking in the paid Semgrep Pro product, CodeQL is able to do so out of the box.
The reason for this is because of how the two tools model source code. Semgrep parses and represents the code as a generic abstract syntax tree. This could be more accurately labelled an abstract semantic tree because it also collapses semantically-equivalent code. Next, it converts this AST into an intermediate language (IL) that can be matched against patterns in Semgrep’s rule syntax.
This parse-to-generic-AST-then-convert-to-IL approach makes it a lot easier to add language support because you only need to worry about the parsing step. However, ASTs are not optimal for taint tracking. The tree structure is not a directed graph, so it cannot directly provide information about data or control flow; you need a data flow graph (DFG) and control flow graph (CFG) for that. The parsing and conversion steps also lose details about language-specific behaviour such as class inheritance and global variable propagation. This is all reflected in the design trade-offs for Semgrep’s taint tracking:
- No path sensitivity: All potential execution paths are considered, despite that some may not be feasible.
- No pointer or shape analysis: Aliasing that happens in non-trivial ways may not be detected, such as through arrays or pointers. Individual elements in arrays or other data structures are not tracked. The dataflow engine supports limited field sensitivity for taint tracking, but not yet for constant propagation.
- No soundness guarantees: Semgrep ignores the effects of
eval-like functions on the program state. It doesn’t make worst-case sound assumptions, but rather “reasonable” ones.
In comparison, CodeQL tries to extract as much relational data including data and control flow on a per-language basis. Instead of parsing each language into a generic AST, it runs a custom extractor for each language. For compiled languages, it even instruments the compiler to extract additional information like standard libraries. Take a quick peek at CodeQL’s go extractor. Each programming language has its own specific set of classes that can be used in a QL query. For example, the Python CodeQL library uses the Call class for function calls while Javascript has CallExpression. This difference arises from each language’s syntax naming conventions.
CodeQL’s approach allows it to make deeper queries with a higher degree of specificity. While there is some lossiness as you move from local to global analysis and from data flow to taint tracking, it does not sacrifice as much power (for lack of a better word) as Semgrep. What it does give up is Semgrep’s ability to quickly support new programming languages and run anywhere; if you are scanning a compiled language codebase and the build step fails, you face hours of debugging.
However, as someone who is actually writing custom rules in both a vulnerability research and DevSecOps context, my main concern is the frontend, i.e. the rule syntax and rule writing experience.
Context Switching 🔗
As far as rule writing is concerned, CodeQL’s QL is an object-oriented programming language. You can avoid this fact for as long as you can while you go through their introductory tutorial, but once you get down to actually writing production-ready rules, it’s time to face reality. You will spend a lot of time reading the CodeQL library documentation, which often lacks usage examples and is a mess of subtypes, (direct and indirect) supertypes, branch types, union types, etc. Before you know it, it’s 3am and you’re trying to understand how FileNameSourceAsSource in semmle.javascript.security.dataflow.ShellCommandInjectionFromEnvironmentCustomizations works. CodeQL tries to help with cheat sheets and boilerplate templates, but the fact remains that writing QL requires a huge context switch from reading code.
In contrast, Semgrep’s pattern syntax looks very much like the actual code you are scanning. You can start with an exact match, then gradually abstract out generic items like variable names and sequences to generalise your rule. You don’t need to worry about programming and can focus on matching. However, I’m concerned that as Semgrep tries to catch up to CodeQL’s taint tracking ability, it’s leaning more and more on its rule syntax to express complex relationships. For example:
pattern-propagators:
- pattern: |
$TO.foo($FROM)
from: $FROM
to: $TO
requires: A
replace-labels: [A, C]
label: B
It’s not immediately obvious what’s going on here with the labels. CodeQL’s advantage is that a lot of taint-tracking complexity is front-loaded in the database building step, whereas Semgrep has to move that complexity to the rule syntax because of how the engine works. There’s also the expressiveness of a query-oriented versus a pattern-oriented syntax.
Iteration 🔗
CodeQL’s killer feature, once you get past the extended setup process, is the VS Code extension. It integrates nicely into something like an IDE for CodeQL rules, allowing you to rebuild databases and visualize rule findings from the user interface instead of CLI. I found this especially helpful for debugging taint tracking queries because you can click directly to the location in the code for each taint step result. It has other features such as unit tests, performance monitoring, and AST visualization.
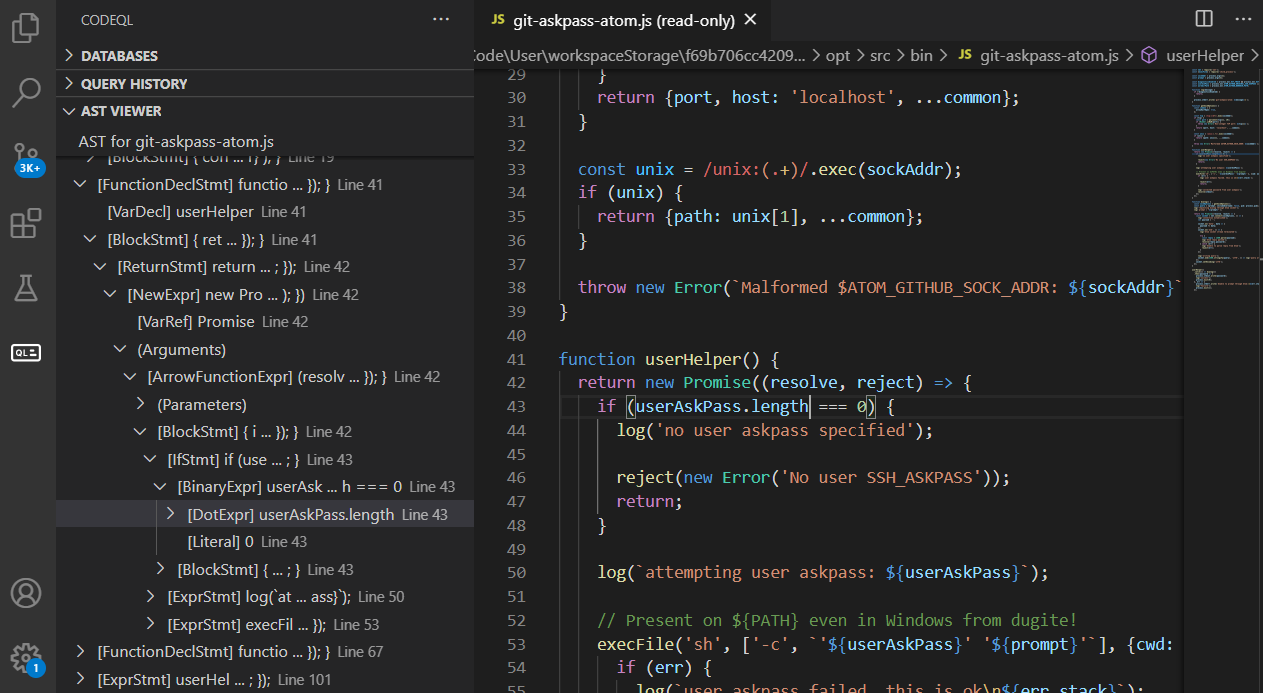
Semgrep’s killer feature for iteration is Semgrep Playground, a web application that allows you to write a test rules in the same window. It helpfully highlights the lines of code matched by your rule so you can quickly correct mistakes. One downside is that it sends all your code to the API server where Semgrep is executed, so it’s not as fast as running Semgrep locally and you must anonymize sensitive code. Fortunately, Semgrep recently announced a Turbo mode that runs Semgrep using WebAssembly in the browser, but it hasn’t been released yet. Meanwhile, Semgrep’s VS Code extension is more focused on developers and SaaS integration, lacking a lot of the features of the CodeQL VS Code extension that make it easier to test rules locally.
Development Environment 🔗
Although Semgrep can be easily installed as a pip package, it doesn’t run on Windows. Sure, you can run this on Windows Subsytem for Linux, but WSL2 takes a huge performance hit on file I/O when accessing the mounted Windows filesystem from the Linux VM. And yes, you can copy source code over to the WSL2 filesystem, but in enterprise environments you need to deal with network shares and VPNs that just don’t play well with WSL2. It adds a layer of unnecessary friction if your machine runs Windows.
While CodeQL’s binaries run on Windows, the setup is a bit more involved because you need to get the workspace configured properly in order to write custom queries. If you try to create a QL rule file on your desktop and run it on a database, it will most likely fail with ERROR: Could not resolve module. This is another reminder that QL is actually a programming language because it needs to load dependencies via a qlpack.yml file first. You can’t just write rules anywhere; you need a “CodeQL workspace”. I wish there was some kind of create-react-app for CodeQL rules, but it already feels like way too much overhead.
Final Thoughts 🔗
Overall, I find Semgrep rule writing easier to get started with, largely due to its approach to querying codebases. I can quickly write a simple rule, iterate, and move on to the results, whereas CodeQL can lead to a rabbit hole of documentation and debugging. However, as you move towards more complex taint tracking queries, you will probably need to start working with CodeQL (or pay for Semgrep Pro).
A lot also depends on your code scanning needs. If you’re building a set of rules for an organization’s DevSecOps pipeline, you want the scans to be fast and compatible with a large, diverse set of codebases without having to worry about something breaking (like a build step). You want minimal false positives because no one has time to triage alerts. Ideally, you want to distribute rule-writing duties and make it easy to train others.
On the other hand, a pentester or vulnerability researcher can handle false positives; you prefer to have less false negatives. Speed is less of an issue because you are running the scan locally instead of in a CI pipeline. You may also be focusing on a smaller set of targets, or even a single codebase. You can invest more time in learning complex rule syntax.
I hope this helps explain why writing CodeQL versus Semgrep rules is so different. I recommend checking out the following materials that go into detail about their backends.