Introduction 🔗
After discovering relatively straightforward memory corruption vulnerabilities in tiny DBF parsers and Apache OpenOffice, I wanted to cast my net wider. By searching for DBF-related vulnerabilities in Microsoft’s desktop database engines, I took one step towards the deep end of the fuzzing pool. I could no longer rely on source code review and dumb fuzzing; this time, I applied black-box coverage-based fuzzing with a dash of reverse engineering. My colleague Hui Yi has written several fantastic articles on fuzzing with WinAFL and DynamoRIO; I hope this article provides a practical application of those techniques to real vulnerabilities.
First, let me give you some context by diving into the history of Windows desktop database drivers.
A Quick History of Windows’ Desktop Database Drivers 🔗
Following the successful release of Windows 3.0 in 1990, the number of Windows applications grew quickly. Many of these applications needed persistent storage. In those days, computer memory was limited, making it difficult for modern server-based databases like MySQL to operate. As such, the indexed sequential access method (ISAM) was developed. To put it simply, ISAM was a file-based method of database storage that included the dBase database file (DBF) format.
As the number of SQL and ISAM database formats increased, Microsoft sought to create a single, common interface for applications to communicate with these databases. In 1992, it released Open Database Connectivity (ODBC) 1.0 which supported various database formats via additional desktop database drivers. One of these drivers was Microsoft’s Joint Engine Technology (Jet) engine consisting of a set of DLLs that added compatibility with different ISAM database formats. For the DBF format, Jet Engine used the Microsoft Jet xBASE ISAM driver (msxbde40.dll).
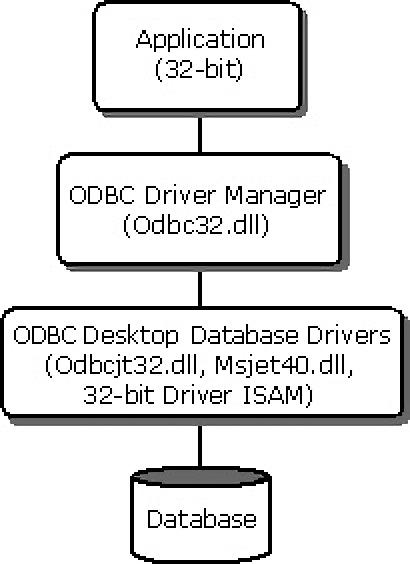
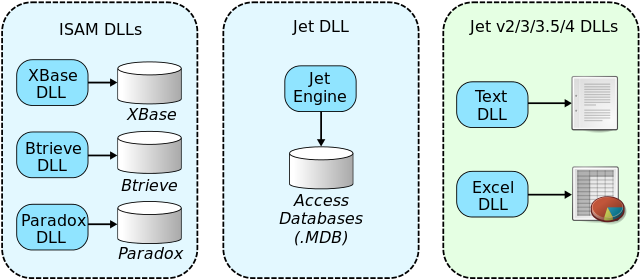
Despite this alphabet soup, both ODBC and Jet engine enjoyed widespread adoption. Many companies also wrote third-party ODBC desktop database drivers for their own proprietary database formats. The inclusion of Jet Engine in Microsoft Access ensured its longevity for more than 30 years, even though it has been largely deprecated by newer technologies such as SQL Server Express. Microsoft Office now uses the Microsoft Office Access Connectivity Engine, a fork of the Jet engine.
To add to the confusion, Microsoft released the Object Linking and Embedding, Database (OLEDB) API in 1996, which acted as a higher-level interface on top of ODBC to access an even greater range of database formats such as object databases and spreadsheets. On top of that, Microsoft released ActiveX Data Objects, an additional API to access OLEDB. Jason Roff attempted to clarify this in the following diagram:
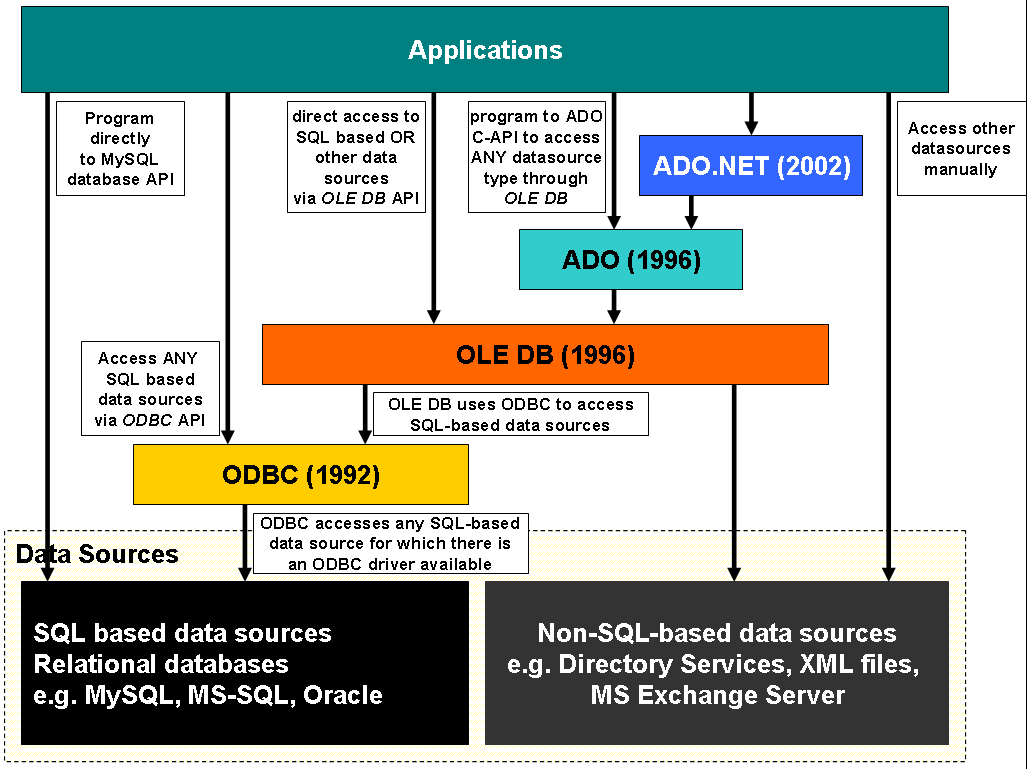
However, you might notice that the diagram misses out that ODBC can also call on the Jet Engine drivers to access non-SQL-based data sources such as DBF! This just goes to show how convoluted Microsoft’s desktop database driver environment has become - even fairly authoritative sources cannot capture the full picture.
Security researchers took advantage of the age and complexity of the OLEDB/ODBC/Jet Engine architecture to discover countless memory corruption vulnerabilities. What made it more attractive was that many important Microsoft applications such as Microsoft Office and IIS rely on this stack. The most recent publication on this topic, “Give Me a SQL Injection, I Shall PWN IIS and SQL Server” presented by Palo Alto researchers at Black Hat Asia 2021, detailed many of these dependencies. In fact, the patchwork architecture was so complex that when Microsoft attempted to deprecate OLEDB in 2011, the number of breakages it caused forced Microsoft to reverse the decision six years later.
Given this context, the Jet Engine was my first port of call for hunting vulnerabilities via the DBF format.
Fuzzing Jet Engine with DBF 🔗
If you have read part one of the series, you should have a pretty good understanding of format-based dumb fuzzing. While this might be a cost-effective way of fuzzing simple targets, modern approaches apply coverage-based fuzzing. In short, these fuzzers rely on compile- or run-time instrumentation to determine which code paths have been reached in each fuzzing iteration. Based on this information, the fuzzer tries to reach as many code paths as possible to ensure proper coverage of the target. For example, let’s take a simple pseudocode function:
function fuzzMe(inputFile){
if (readLine(inputFile)[0] === opcode1) {
runOpCode1(inputFile[1:]);
} else if (readLine(inputFile)[0] === opcode2) {
runOpCode2(inputFile[1:]);
} else {
die();
}
}
If the fuzzer mutated the input file to match the first condition, it would know that it had reached a new code path to fuzz further. It would save that mutation (first byte matching opCode1) and continue to mutate on top of that saved mutation. This would ensure that rather than wasting time on the fall-through condition (else { die(); }), the fuzzer was reaching deeper into possibly vulnerable code in runOpCode1. This approach is incredibly powerful and most modern fuzzers are coverage-guided, including my fuzzer of choice WinAFL by Google Project Zero.
Since instrumentation is a computationally expensive operation, coverage-based fuzzers should run on a harness. Imagine a large office application that loads a xyzFormat module and runs the xyzFormat.openXyz function whenever it opens an XYZ file. We could fuzz this by using the large office application to open mutated XYZ files repeatedly, but this would be extremely time- and resource-intensive with coverage-guidance instrumentation. Instead, why not write our own mini-program, or harness, to import the xyzFormat module and run the xyzFormat.openXyz function directly? This would involve reverse-engineering the function call and feeding the right inputs, but greatly speed up fuzzing. There’s a lot more to discuss here, but if you want a quick guide on coverage-based fuzzing with WinAFL, check out Hui Yi’s blogpost.
As I mentioned, fuzzing Jet Engine was a well-travelled path. After consulting the Palo Alto researchers, I decided to build a harness based on the Microsoft OLE DB Provider for Microsoft Jet. The researchers noted that opening the mutated files and executing a few simple queries were sufficient for a successful harness. Hence, I used the CDataSource and CCommand classes as described in Microsoft’s OLEDB programming documentation to open the mutated file (CDataSource.OpenFromInitializationString/CSession.Open), execute a select all query (CCommand.Open), retrieve the column information (CCommand.GetColumnInfo), and finally iterate through the row data (CCommand.GetString). In turn, these OLEDB functions depended on the Microsoft Jet OLEDB provider (msjetoledb40.dll) which used Jet Engine (msjet40.dll).
Here, I hit a roadblock. Even though I could fuzz Jet Engine via OLEDB using the Microsoft.Jet.OLEDB.4.0 connection string, I faced many difficulties setting up Jet Engine on my fuzzing environment. Jet Engine was deprecated and did not interact well with my updated environment. After a bit of tinkering, I decided to switch targets and fuzz the Microsoft Access database engine (acecore.dll) via the Microsoft Access OLEDB Provider (aceoledb.dll) instead. To parse a DBF file, the Access database engine would call on its own xBASE ISAM (acexbe.dll). Since my ultimate target was Microsoft Office, it made sense to fuzz the Access Database Engine instead of Jet Engine. Furthermore, since DBF support was removed, then added back to Access in 2016, there was a chance that some interesting code could have been included. Thus, I switched to the Microsoft.ACE.OLEDB.12.0 connection string.
Next, I minimised the DBF sample corpus with winafl-cmin.py, which selected the smallest set with the greatest possible coverage. Finally, I could start my fuzzer! Or rather, my fuzzers - I ran twelve instances simultaneously thanks to WinAFL’s parallel fuzzing support.
The Mystery of the Ghost Crashes 🔗
As the fuzzers worked in the background, I continued researching other office applications that parsed DBF files. No crashes occurred immediately, but I figured that this was normal since my fuzzing machine was rather slow. This continued for several days, until I checked one morning and found a bunch of crashes!
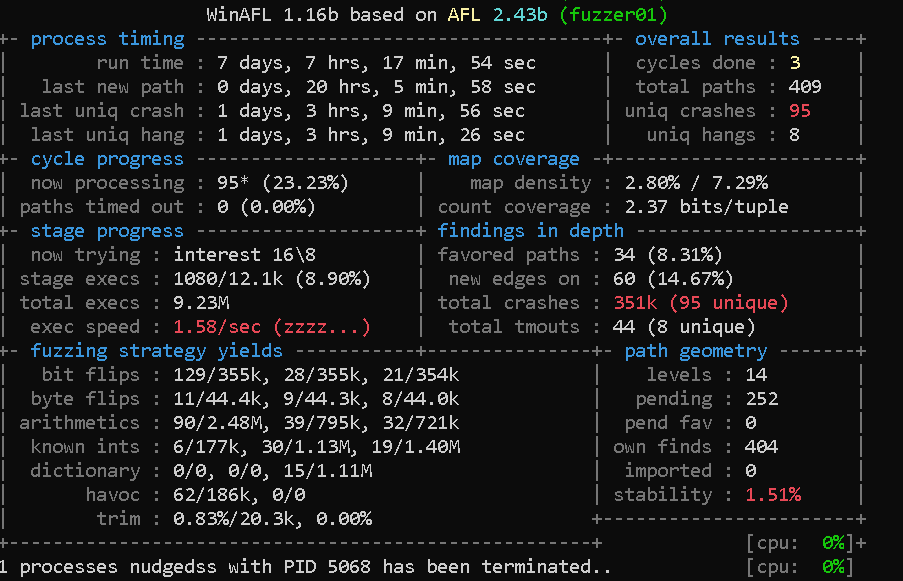
WinAFL saved the mutated file that caused each crash in the crashes folder with the error in the filename, such as EXCEPTION_ACCESS_VIOLATION.
To reproduce the vulnerability, I downloaded the crashing files to a virtual machine with the same OLEDB and Microsoft Access database engine environment, then opened the files with the harness. However, the crash no longer occurred! Even when I inspected the harness execution with WinDBG, nothing stood out; the harness opened and parsed the mutated DBF file without any issues.
What was going on?
I went back to the fuzzing machine and ran the harness with the crashing files. No error.
After much head scratching, I attribute it to a false positive and returned to researching other office applications while the fuzzers continued to run. Meanwhile, the crashes stopped occurring.
A few hours later, the same thing happened! Confused, I checked the files on my fuzzing machine; this time, they managed to crash the harness.
I began to put two and two together. There had to be some difference between the fuzzing machine and the debugging machine that caused the discrepancy. After a few hours of painstaking debugging, I made a discovery: one of the office applications I had installed on my fuzzing machine as part of my research appeared to be causing the crashes.
When I uninstalled the office application (which will remain unnamed), the crashes stopped. When I re-installed it, the mutated files crashed the harness again.
Digging deeper, I ran a stack trace on the crash:
0:000> k
# ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
00 00f7e360 10e57fc8 IDAPI32!ImltCreateTable2+0x3c6b
01 00f7e38c 67940c19 IDAPI32!DbiOpenTableList+0x31
02 00f7e888 67947046 ACEXBE+0x10c19
03 00f7f110 6794a520 ACEXBE+0x17046
04 00f7f140 6794a295 ACEXBE+0x1a520
05 00f7f15c 5daf71ae ACEXBE+0x1a295
06 00f7f184 5db421cb ACECORE+0x171ae
07 00f7f2c8 5db22f1e ACECORE+0x621cb
08 00f7f360 5db224fe ACECORE+0x42f1e
09 00f7f51c 5db21f8d ACECORE+0x424fe
0a 00f7f640 5db20db2 ACECORE+0x41f8d
The crash occurred in IDAPI32, which was called by ACEXBE (remember that this is the Microsoft Access xBASE ISAM). Where had this come from? A quick Google for “IDAPI32” revealed that this library was the “Borland Database Engine library”. Huh? Puzzled, I checked the path to the library: c:\Program Files\Common Files\Borland Shared\BDE\IDAPI32.DLL.
Then, it clicked. The unnamed office application had installed the Borland Database Engine (BDE) as a dependency. Somehow, once this was installed, the Microsoft Access database engine xBASE ISAM switched to BDE to parse the DBF files. How did this happen?
Looking through the disassembled code of ACEXBE in IDA Pro, I discovered where it loaded IDAPI32:
.text:1000E1B3 sub_1000E1B3 proc near ; CODE XREF: sub_1000F82F:loc_1000F9DD↓p
.text:1000E1B3
.text:1000E1B3 Type = dword ptr -428h
.text:1000E1B3 cbData = dword ptr -424h
.text:1000E1B3 phkResult = dword ptr -420h
.text:1000E1B3 Destination = word ptr -41Ch
.text:1000E1B3 Data = word ptr -210h
.text:1000E1B3 var_4 = dword ptr -4
.text:1000E1B3
.text:1000E1B3 push ebp
.text:1000E1B4 mov ebp, esp
.text:1000E1B6 sub esp, 428h
.text:1000E1BC mov eax, ds:dword_10037408
.text:1000E1C1 xor eax, ebp
.text:1000E1C3 mov [ebp+var_4], eax
.text:1000E1C6 push edi
.text:1000E1C7 lea eax, [ebp+phkResult]
.text:1000E1CD push eax ; phkResult
.text:1000E1CE push 20019h ; samDesired
.text:1000E1D3 push 0 ; ulOptions
.text:1000E1D5 push offset SubKey ; "Software\\Borland\\Database Engine"
.text:1000E1DA push 80000002h ; hKey
.text:1000E1DF call ds:RegOpenKeyExW
.text:1000E1E5 test eax, eax
.text:1000E1E7 jz short loc_1000E1F0
.text:1000E1E9 xor eax, eax
.text:1000E1EB jmp loc_1000F54A
...
.text:1000E28E loc_1000E28E: ; CODE XREF: sub_1000E1B3+13E↓j
.text:1000E28E push edi ; SizeInWords
.text:1000E28F lea eax, [ebp+Destination]
.text:1000E295 push eax ; Destination
.text:1000E296 push esi ; Source
.text:1000E297 call sub_10007876
.text:1000E29C mov eax, ebx
.text:1000E29E sub eax, esi
.text:1000E2A0 and eax, 0FFFFFFFEh
.text:1000E2A3 cmp eax, 20Ah
.text:1000E2A8 jnb loc_1000F559
.text:1000E2AE xor ecx, ecx
.text:1000E2B0 mov [ebp+eax+Destination], cx
.text:1000E2B8 lea eax, [ebp+Destination]
.text:1000E2BE push edi
.text:1000E2BF push eax
.text:1000E2C0 push offset aIdapi32Dll ; "\\IDAPI32.DLL"
.text:1000E2C5 call Mso20Win32Client_1065
It appeared that the Access xBase ISAM included a hard-coded check for the BDE path and would run BDE if it existed! Since BDE was a long-deprecated library, with the last version released in 2001 according to WaybackMachine, this was a classic example of CWE-1104: Use of Unmaintained Third Party Components. There were undoubtedly numerous vulnerabilities left over in this classic piece of software that led to the crashes.
I have explained the technical reason for the crashes. However, to understand how an almost thirty-year-old library ended up in the code of the Microsoft Office Access Database engine, we need to understand the history of the Borland Database Engine.
A Quick History of the Borland Database Engine 🔗
In the 1980s, dBase was one of the first tools used by early software developers to build applications. Comprising a database engine and its own programming language, it grew massively due to its first-mover advantage and inspired legions of copycats such as FoxPro. A competing dBase standard called “xBase” was created to distinguish itself from dBase’s proprietary technology. Many consumer applications back then were written using dBase tools and its derivatives.
In 1991, then-software giant Borland acquired Ashton-Tate, the owner of dBase. However, competition was heating up with an upstart company named Microsoft, which acquired FoxPro and launched its own Microsoft Access database engine. To shore up its product line-up, Borland also acquired WordPerfect, eventually launching its own Borland Office suite that included DBF compatibility.
Over time, Borland failed to keep up with Microsoft as it was forced to adapt to constant changes in the very platform it was developing for - Windows. Eventually, dBase, WordPerfect, and other core Borland products ended up being sold in pieces to various companies. By 2009, Borland was finished - acquired by Micro Focus for $75 million, a shadow of its former self. It’s hard to win a war on your opponent’s turf.
However, the deep impact dBase made in early software development continues today. After all, Microsoft Access still includes a legacy xBase ISAM engine. Even the choice of “xBase” instead of “dBase” reflects the cutthroat corporate wars of the past.
Big Database Energy 🔗
Back to the Borland Database Engine itself. When I realised the crashes were occurring in the IDAPI32 library, I decided that it would be better to fuzz the IDAPI32 library functions such as DbiOpenTableList and ImltCreateTable2 directly instead of via the high-level OLEDB API. Thankfully, there are still a few tutorials and code snippets online that demonstrate how to call BDE functions to read a DBF file. I had to import several custom structs to support the harness, which ran dbiOpenTable and dbiGetNextRecord to open and parse the database. This removed a lot of the processing overhead of the OLEDB API and allowed me to pinpoint crashes more accurately.
As the crashes stacked up, it was time to triage them. Unlike Peach Fuzzer, WinAFL did not have a convenient triaging helper, but I could easily recreate it using the WinDBG command line interface and PowerShell:
Get-ChildItem "C:\Users\fuzzer\Desktop\crashes" -Filter *.dbf |
Foreach-Object {
& 'C:\Program Files\Windows Kits\10\Debuggers\x86\windbg.exe' -g -logo C:\Users\fuzzer\Desktop\windbglogs\$_.Name.log -c '.load exploitable;!exploitable;!exchain;q' C:\Users\fuzzer\Desktop\BDEHarness\BDEHarness.exe $_.FullName | Out-Null
}
The script iterated through all the crash files, ran them using the harness in WinDBG, then generated a log file containing the !exploitable output. Next, I focused on the EXPLOITABLE crashes and grouped the ones that had the same crashing instructions.
Right off the bat, two crashes stood out to me.
The Second Order EIP Overwrite 🔗
The first crash looked like this:
0:000> r
eax=29ae1de1 ebx=00000000 ecx=1c3be2dc edx=015531a0 esi=1c3bfa4c edi=01553c1c
eip=1bd2f8cd esp=01552e54 ebp=01553808 iopl=0 nv up ei pl zr na pe nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00210246
IDAPI32!ImltCreateTable2+0x3c6b:
1bd2f8cd ff10 call dword ptr [eax] ds:0023:29ae1de1=????????
This was extremely promising because it looked like I had overwritten the EAX register, which was then used in a call instruction. This meant that I could control the execution flow by changing which address the program would jump to. Just like in my dumb fuzzing workflow, I created a “minimal viable crash” to pinpoint the source of the overwritten EAX bytes.
However, even after minimising the file to the essential few bytes, I realised that none of the bytes in my mutated file matched the overwritten EAX! This was strange, so I searched the application memory for 29ae1de1 to trace back to its source. I realised that these bytes appeared to be coming from the same region of memory but varied based on the value of lengthOfEachRecord in my file.
If you recall from part one, the format of the DBF header looks like this:
struct DBF {
struct HEADER {
char version;
struct DATE_OF_LAST_UPDATE {
char yy <read=yearFrom1900,format=decimal>;
char mm <format=decimal>;
char dd <format=decimal>;
} DateOfLastUpdate;
ulong numberOfRecords;
ushort lengthOfHeaderStructure;
ushort lengthOfEachRecord;
char reserved[2];
char incompleteTrasaction <format=decimal>;
char encryptionFlag <format=decimal>;
int freeRecordThread;
int reserved1[2];
char mdxFlag <format=decimal>;
char languageDriver <format=decimal>;
short reserved2;
} header;
Based on the minimal viable crash, the overflow occurred due to an arbitrarily large lengthOfEachRecord, which caused an oversized memcpy later. In turn, the last byte of lengthOfEachRecord changed the address of the value that EAX was later overwritten with.
Here’s a helpful graphic to illustrate this point(er).

However, it appeared that the crash only occurred within a certain range of values of lengthOfEachRecord. By painstakingly incrementing the last byte, I enumerated these values:
| lengthOfEachRecord | EAX Source Address | EAX |
|---|---|---|
| 08 FE | 106649b6 | 46424400 |
| 18 FE | 106649c6 | 41424400 |
| 28 FE | 106649d6 | 45534142 |
| 38 FE | 106649e6 | 3b003745 |
| 48 FE | 106649f6 | 595e1061 |
| 58 FE | 10664a06 | 53091061 |
| 68 FE | 10664a16 | 00000000 |
| 78 FE | 10664a26 | 60981061 |
| 88 FE | 10664a36 | ab391061 |
| 98 FE | 10664a46 | 5c450000 |
| A8 FE | 10664a56 | 65b81061 |
| B8 FE | 10664a66 | a7b40000 |
| C8 FE | 10664a76 | 00000000 |
| D8 FE | 10664a86 | 6f0e1061 |
| E8 FE | 10664a96 | 29ae1061 |
| F8 FE | 10664aa6 | 80781061 |
To get my desired code execution, I needed to ensure that the pointer overwrite chain ended at attacker-controlled bytes. I checked each of the potential values of EAX for useful addresses. Unfortunately, none of them pointed to attacker-controlled bytes; while some pointed to unoccupied memory addresses, the rest pointed to other sections of unusable code. I tried overflowing into some of these addresses, but the bytes wrapped around in a way that prevented this from happening. Perhaps the area of memory that contained the possible EAX source addresses was written after the initial overflow.
In the end, I gave up this promising lead as it only caused an indirect execution control at best. On to the next.
The Write-What-Where Gadget 🔗
The second crash looked like this:
(26ac.26b0): Access violation - code c0000005 (first chance)
First chance exceptions are reported before any exception handling.
This exception may be expected and handled.
eax=00000000 ebx=00000000 ecx=00000008 edx=00000021 esi=6bde36dc edi=00490000
eip=4de39db2 esp=00b4d31c ebp=00b4d324 iopl=0 nv up ei pl nz na po nc
cs=001b ss=0023 ds=0023 es=0023 fs=003b gs=0000 efl=00010202
IDDBAS32!BL_Exit+0x102:
4de39db2 f3a5 rep movs dword ptr es:[edi],dword ptr [esi]
0:000> k
# ChildEBP RetAddr
WARNING: Stack unwind information not available. Following frames may be wrong.
00 00b4d324 4de00cd8 IDDBAS32!BL_Exit+0x102
01 00b4d344 4de019f6 IDDBAS32!XDrvInit+0x1fb7c
02 00b4d370 4ddfc2a9 IDDBAS32!XDrvInit+0x2089a
03 00b4d4d0 4ddee2cd IDDBAS32!XDrvInit+0x1b14d
04 00b4d9d0 4dde2758 IDDBAS32!XDrvInit+0xd171
05 00b4da0c 4bdff194 IDDBAS32!XDrvInit+0x15fc
06 00b4dcc0 4bde5019 IDAPI32!ImltCreateTable2+0x3532
07 00b4de18 79587bb3 IDAPI32!DbiOpenTable+0xcd
At first glance, this appeared less promising than the EIP overwrite. The references to [edi] and [esi] suggested that indirect addressing would be necessary, and rep movs seemed like a cumbersome instruction to deal with.
On closer inspection, however, I realised that this was one of the most powerful memory corruption gadgets: a write-what-where. The rep movs instruction copies the bytes at [ESI] to [EDI] ECX times. After creating my minimal viable crash, I found that ESI, EDI, and ECX were all controllable via bytes in the payload file and I could write arbitrary bytes anywhere in memory!
The minimal viable crash also underscored the strength of coverage-guided fuzzing. To reach this crashing instruction, fieldName must be set to \x00 to trigger the buffer overflow by causing a copy of the rest of the payload bytes into a zero-length string buffer. On top of that, two other bytes corresponding to the languageDriver byte in the header and an offset in the body had to be set to specific values to reach the crash. This was a hallmark of coverage-guided fuzzing: discovering and eventually crashing edge-case conditions in a complex codebase.
Now that I could write arbitrary bytes to memory, the next step was to execute my own code. Thankfully, given the age of the IDDBAS32 library, it was compiled without any memory protections like Data Execution Prevention (DEP) or Address Space Layout Randomisation (ASLR). As such, I could build a straightforward Return-Oriented Programming (ROP) chain exploit that overwrote a fixed return pointer after the malicious overwrite, then worked its way through GetModuleHandleA > GetProcAddress > WinExec.
With the new payload, my harness executed the overwrite and popped Calc.exe without a hitch. Filled with excitement, I opened Microsoft Office Access and added the payload as an external database. It crashed… with no Calculator. What happened?
As it turned out, even though IDDBAS32 was compiled without memory protections, Microsoft Office has enabled Forced ASLR since 2013, which adds address randomisation to loaded libraries even if they were not compiled with it. This stumped quite a few adversaries in the past, such as this CVE-2017-11826 exploit sample analysed by McAfee researchers. In my case, since the addresses of IDDBAS32 were randomised, my exploit was sending the instruction pointer to random addresses instead of the start of my ROP chain.
In such cases where you can no longer rely on non-ASLR modules, the only option is to leak addresses through a memory read gadget. This is much easier to do in a scripting context like JavaScript for a browser exploit. You can run the memory address leak exploit first before your memory write exploit. When opening a database or document in Microsoft Office, however, your options become a lot more limited unless you rely on macros, which is not the ideal exploit scenario. Fortunately, CVE-2021-40444 also highlighted another scripting environment in Office: ActiveX. As another researcher noted on Twitter, this creates another path to bypass ASLR by loading stripped DLLs.
Regardless of your choice of ASLR bypass, once the addresses are correctly aligned, the exploit runs on Access smoothly:
With the exploit completed, I reported the vulnerability at the Microsoft Security Response Centre.
- 25 June: Initial disclosure
- 7 July: Case opened
- 16 July: Vulnerability confirmed
- 14 September: Fix released (Patch Tuesday)
- 18 September: Public Disclosure
Conclusion 🔗
The dBase vulnerability was an accidental find that surfaced from the depths of computing history. (Un)surpisingly, a thirty-year-old format continues to cause problems in modern applications. Even though the Borland Database Engine was deprecated decades ago, some software manufacturers continue to package it as a dependency, exposing users to old vulnerabilities. The engine is no longer updated and should not be used in software.
For me, it was a useful opportunity to take one step beyond foundational memory corruption skills by exploiting a write-what-where gadget to achieve code execution. It also demonstrated the power of black-box coverage-guided fuzzing in a vulnerability research workflow. I hope this sharing proves useful for other beginners.